
New Data
More Little Wins
July 12, 2016
by Ash Smith
It was recently pointed out to us here in Open Data HQ that we don’t blog enough. We do a lot of things but most of them are little wins and not worth their own blog post. However, we’ve had enough little wins recently that it’s worth writing a paragraph or two about all of them.
Public People IDs
We have always had a few datasets containing information about people. The ePrints dataset, the public phonebook and, more recently, the facilities data all contain people triples. Sadly none of them linked up. This obviously troubled me.
We’ve always been a little timid around personal data. It’s a tough area – one wrong move and you’ll never live it down. Some businesses have been forced to close down due to poor management of personal data. Also, what some might consider acceptable some may not. I notice trends around the University – for example, most people in WAIS already have a public ‘people’ page, containing their email address, their degree and maybe a few other things, and see no wrong in it at all. Researchers actually need a public identity on their institutional website, it’s the way they communicate with other researchers and increase their reputation. But if I were to tell the groundskeeper or the staff in catering that their email addresses and photos are all going to be made public, they would probably be quite strongly opposed to the idea, and quite rightly so. I have no right to publish their personal information without their permission, and certainly not as open data.
We believe we have a compromise. We’ve assigned everyone in the University a URI, but that’s it. Occasionally these URIs resolve to something other than a blank page, but this only currently happens if (a) they have explicitly agreed to be in the public phonebook, (b) are the contact for a piece of equipment in our equipment database, or (c) I’ve added a bunch of information just for laughs (see http://data.southampton.ac.uk/person/D5mY.html for an example.) Even these pages are not visible to Google, and they are not centrally linked from anywhere so you can’t just scrape all the public people (unless you use the SPARQL endpoint I guess). But the point is that even people who have given us permission to publish their information are quite well hidden from Bad People™, and nobody else is public at all, even though we can refer to them in other datasets if we need to. I’m working with the team responsible for the recent main website re-brand, so I’ll link all this in with actual departmental people pages when I can. The main point is that everyone has a URI now, and these URIs are completely obfuscated and non-sequential, and (externally, at least) there is absolutely nothing you can do with them unless the person to which it refers is OK with their data being public. But we can use them to refer to people, and you can be sure the person referred to within one dataset is the same person being referred to by another.
An interesting quirk we encountered (hopefully before it caused any problems!) was what we lovingly refer to as the ‘four letter word problem’. The URIs referring to people were created by generating random numbers starting at over a million (so nobody gets to be ‘number 1’) and then base64-encoding them. The result is a four-digit alphanumeric string which means nothing, and this gets added to the URI. Someone pointed out to us that we run the risk of accidentally generating something along the lines of ‘D0rk’, and the poor person who gets assigned this ID won’t be too happy. Realising there are other (often far worse) four-letter words that might be accidentally generated, we found a digital copy of the dictionary and cross-checked every ID we’d generated and re-generated it if it was a dictionary word. Now whenever we generate a new ID, for a new member of staff, we check against a dictionary before ‘releasing’ the URI into the wild.
Waste Map
http://tools.southampton.ac.uk/waste-map/
This is an embeddable map of all the waste points on our many campuses. It’s particularly useful for people living in halls of residence, but is also used by Estates and Facilities when working with external contractors.
Nightingale Foyer Report
In the Nightingale building foyer there is a little touch-screen display from which anyone can look up the people who work in that building. The data comes from the Open Data Service, but we had to build a custom version of the data because of the embedded staff from professional services who also work in the building alongside the Nursing and Midwifery staff.
Room Shapes and Divisions
You will almost certainly have seen our lovely digital map, for which I am eternally grateful to Christopher Baines. It uses data from Open Street Map and our own open data, but in many cases where data does not exist, Chris went and created it anyway. The best example of this are the room shapes. Zoom in as far as you can on the map and the building shapes will open up into partial floor plans. We are actually not allowed to publish full floor plans for security reasons, but publicly accessible rooms are fair game. I’m currently working on a more maintainable version of the map, so I’ve taken the opportunity to convert all of Chris’ lovely polygons into an RDF description and published them as a dataset.
Additionally, I was asked a long time ago by one of the lab managers in Building 32 if the bays had URIs. The whole of levels 3 and 4 of Building 32 make up a big open plan lab area for Web Scientists, and this is split into bays of four to six people. At the time the bays didn’t have any URIs but I figured that because I’m the University’s only Linked Open Data specialist, it’s probably my job to assign them! So I did, and built a dataset describing their physical position within the lab.
ATMs
We’ve always had a list of ATMs on campus as part of the Amenities dataset, but that’s as far as it goes. A colleague of ours, Martin Chivers, suggested we include the location of all the ATMs in Southampton, and that the information is all available from various websites already. A few hours of googling added to my own personal knowledge and we now have a spreadsheet of ATM points for the central Southampton and Highfield areas. I’ll try to keep it up to date but the amenities dataset is manually maintained so I apologise if I miss one or two. Looking to the future, I believe we can keep this up to date automatically using Open Street Map, although this is basically crowd-sourced data and we’d like something better. The Link website actually contains a search engine for ATMs in Southampton, but this is almost certainly not open data and we have no right to republish it. So this remains an ongoing project.
Open Day Events
We’ve had lists of open day events before, but this year someone has already gone through the hassle of entering them all into our mobile app, MySouthampton. One Android phone and a copy of WireShark later and I’ve worked out where it gets its data and mercilessly stolen it! This of course means that the open data is up-to-date as long as MySouthampton is. I’ve described the events in the same way as we currently do seminars, etc, so you can always tell when it’s open day because suddenly all the buildings pages have enormous lists of events.
Building Entrance Data
August 7, 2014
by Ash Smith
The University’s Web and Internet Science research group recently had their annual “WAIS Fest”. This is a few days every year in which the researchers all down tools and do something fun and interesting. It gives them all a chance to work with people they may not always work with – important in such a large research group – but also it allows the group to try some things they may not normally be able to get done in their normal line of work. WAIS Fests are nearly always productive. In the past, WAIS Fest themes have actually become the basis of prize-winning research publications, and even started funding bids. The Open Data Service have benefited from these events in the past, which is why we always make a point of getting involved.
This year, I ran my own theme: crowdsourcing data. We’re getting pretty good at getting information from the various sub-organisations of the university, usually by showing that linking open data makes it greater than the sum of its parts. But there is some information that simply doesn’t exist in any University system, and one thing we are missing is entrance and exit information for the buildings on campus. Buildings and Estates don’t keep this information, so it’s up to us to get hold of it somehow. So our idea was to come up with a way of making it simple to curate a dataset in this way. The other nice thing about Estates not having official identifiers and descriptors for building portals is that we got to make our own, and craft the URIs as we like.
We were actually dealt a useful trump card in our quest. Our team was made up of Chris and myself, and also Alex Hovden, a WAIS summer intern. Alex uses a motorised wheelchair to move about and has had a few problems operating some of the lab doors, which are not easy for wheelchair users to operate. So when Alex volunteered to go around campus making notes of the locations of building doorways, we decided he should note down which doors he could not access, and list this in our data as well.
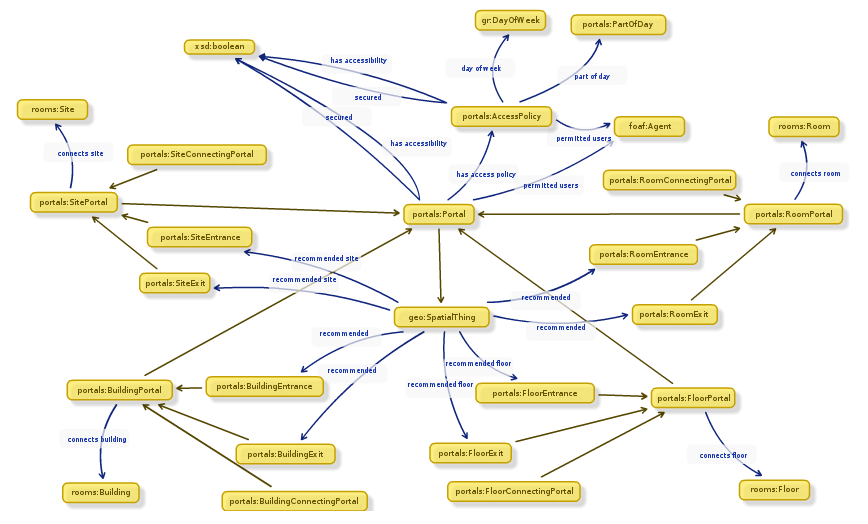 While Alex was off collecting data, Chris and I designed an ontology to describe entryways in linked data. It’s a lot harder than it sounds. To design our ontology we used Neologism, which is an excellent web-based tool for generating ontologies quickly, but the actual modelling process was where most of the work was. We opted for the umbrella term ‘portal’ as it nicely covers all possible entrances to things without explicitly stating entry or exit. A doorway is a portal, so indeed is a tunnel or a bridge. We also had disagreements as to whether or not security properties should be lumped together with access methods, and whether entrance/exit should be a property or a sub-class of the portal class. The task did get a bit serious once or twice as we started considering whether saying “Open Sesame” would count as an access method, and whether or not we should mention pre-1988 daleks in our description of a door with steps (we did.)
While Alex was off collecting data, Chris and I designed an ontology to describe entryways in linked data. It’s a lot harder than it sounds. To design our ontology we used Neologism, which is an excellent web-based tool for generating ontologies quickly, but the actual modelling process was where most of the work was. We opted for the umbrella term ‘portal’ as it nicely covers all possible entrances to things without explicitly stating entry or exit. A doorway is a portal, so indeed is a tunnel or a bridge. We also had disagreements as to whether or not security properties should be lumped together with access methods, and whether entrance/exit should be a property or a sub-class of the portal class. The task did get a bit serious once or twice as we started considering whether saying “Open Sesame” would count as an access method, and whether or not we should mention pre-1988 daleks in our description of a door with steps (we did.)
Once we had a way of representing the data, it was quite a simple task of writing a script to generate triples from Alex’s spreadsheet, and modifying the pages on data.southampton.ac.uk that describe buildings. Chris also built a smaller, hand-maintained file that lists common learning spaces such as lecture theatres, and which external door is the closest. This is now listed on the room pages, such as on this page about a lecture theatre in the Life Sciences building. Although they’re still lacking information on entry method and access restrictions, we now have a page for all the building external doors on campus that we know about, such as this page, about the south entrance to Building 2, which explains that the entrance has steps and is not easily accessible by people in wheelchairs.
Of course there are always things that don’t go to plan, and we need to learn more about certain things. One idea Chris had for getting latitude/longitude points of the doors was to leave the GPS on his phone on while taking photos of each door, and also take a photo of his feet stood next to each door with the intention of pulling the GPS information from the photo’s EXIF meta-data. This didn’t go as planned because the GPS on some phones isn’t very accurate, and although all of the geo-tagged photos were clearly on campus, many were next to the wrong building. We had plans to ask people to crowdsource spacial data by asking people to send us geo-tagged photographs, but this clearly won’t work.
The other thing we discovered is that RDF is a great way of representing this data because you can simply leave out the bits you don’t know. For example, there were several doors to which we don’t have access, and it’s not always obvious how a door opens unless you can actually open it. We were trying to list which doors require you to push or pull, which open with a push-button and which are on a sensor. It’s usually obvious which doors are on push-button, but unless you can actually see the door opening you can’t determine whether they’re manual or sensor-controlled. It doesn’t help that some things change based on time of day. For example, the doors on building 32 are sensor-controlled during the day, but become card access in the evening.
To conclude, it was another very beneficial WAIS Fest, as the output was not just a new, permanent feature for the Open Data website, but also we learned a lot about crowdsourcing, as well as the design of ontologies that describe something seemingly simple like doorways. The work we did will not just benefit lost students and members of staff, but will also hopefully benefit those with accessibility problems such as wheelchair users.
Open Data Open Day – Hackers summary
June 27, 2013
by Patrick McSweeney
As you know from Ash’s previous post ran an Open Data Open Day for people in the University to come and learn about open data. As part of the event we invited the University top hackers to come and do some open data hacking. The template is one familiar to many of you who have attended our events or JISC hack days before. Simply get hackers to sit down together, form into teams of 2-5 people, give them a blank slate, float some ideas, keep coffee on tap and periodically wheel food in and out. At the end of the day go to the bar so that each team can present what they have been working on over a hard earned beer.
One of the key aims for the day was to link up people who had data with people who could do something cool with it. The hack day is a good way to do this because you have a room full of people who can do something cool. Then over the course of the day people with data drop by and talk to the hackers, tell them about there data and get ideas to do cool stuff. It is a friendly and informal environment to work in and people come out with some really good ideas. What always surprises me is, even though I have participated in at least 30 and run at least 5, the outputs from the day are always so amazing good. This hack day was no exception and our teams came out with a combination of the awesomely cool and mind-bogglingly useful stuff.
The outputs were:
LOD Search and the data.southampton.ac.uk usability study
Collin Williams (CISCO Systems) , Rikki Prince, Biscuits Newton and Andreas Galazis Decided the usability of data.southampton.ac.uk was not good enough for non-technical people. They performed a usability study of the site and identified key areas of weakness to feed back to us. The biggest problem they found was that the search on data.southampton was nearly unusable. To combat the problem they created LOD Search, a SPARQL smart search indexing tool which can generate a usual search engine on any SPARQL end point. The demo they presented was very very impressive and prompted a lot of questions from the audience. Attempts to trip up the system by asking for difficult things gave it no trouble at all and the interface was surprisingly good given the short time available to work on it.

Adam Field (iSolutions), Matt Smith (iSolutions) and Lisha Chen-Wilson (iSolutions) met Adam Tewksbury from the University transport office. He was looking for a cool map and video of cycle routes which he can embed in the transport website and attach to the open data pages and maps. The team took helmet cam videos and GPS data about the route and combined them to make cool video which moves the pointer on an open street map as the the video plays. The technique is very powerful and reproducible for any combination of video and GPS data in KML or CSV format. Hopefully this will result in more students and staff getting on to their bikes to cycles the safe routes of Southampton.

Exchange Calendar to iCal
Martin Chivers (iSolutions) spent a chunk of the morning in talks learning about the nuts and bolts of open data. In the afternoon he grabbed a laptop and cracked really big data.southampton.ac.uk walnut. He created a commandline tool which exports a exchange calendar as iCal. One of our big bug bears in open data has been getting data out of exchange and this tool hit the problem squarely on the head. In the past we have had to ask users with temporal data to set up an account on Google calendar since we can get data out of it but not from our own exchange server. Now users will be able to work in their normal workflow without having to use a tool outside of the University to do a fair ordinary task. As a demo he was kind enough to give us the iSolution change management calendar as open data.
Exchange Calendar to iCal on github

Southampton Blackout the real story
Tyler Ward (ECS) was more of a victim of circumstance than a hacking volunteer at our Hack Day. He was collocated with us to work on ECS’s media sensation Erica the Rhino but since he is keen got caught up in the open data hackery. The University of Southampton ran a media campaign called the Southampton Blackout to promote efficient power use at the University. The write up from our Comms team had some interesting mathematical inaccuracies which made the integrity of the finds questionable. Tylers aim was to use open energy usage data to tell the real story of the Southampton blackout. What he found is that some buildings during the blackout were using more energy not less to a level which almost eclipses the savings made in other buildings. He found some interesting trends in the data particularly in the figure below for ECS Mountbatten Silcon Fab lab. His close analysis of data was able to deduce where future campaigns should be targeting next an where savings can be made most easily.

All in all the day was a great success and lots of fun for the hackers involved. To quote Adam Field:
I had fun. It’s not often that I can take a problem and spend a day solving it.
New Feature! The Room Finder
March 19, 2013
by Ash Smith
We now have a tool that allows anyone in the University to find a suitable room for their event. We call it the Room Finder and I for one am rather proud of it. The tool pulls data from the places dataset, the room features dataset and the new room bookings dataset, and is a really simple way of finding a room at the University of Southampton. Let’s say, for example, that you need a room for a lunchtime meeting on Friday somewhere on Highfield Campus – and by the way, the room must contain a data projector and a piano. Using the Room Finder, you can check to see if such a room is available at the time you need and, if so, click through to the room description pages to find out more. The tool doesn’t currently allow you to actually book the room, but it’s hoped that many phone calls to Estates and/or the central booking service can now be avoided as we continue our ongoing mission to get all the University’s useful data onto the web.
The Room Finder is still under development, so things will change in the coming days. Specifically, I’m not completely happy with the way it displays the features list, it’s still a little bit more technical than it needs to be. We’re also hoping to get a mobile version out soon, it’s a bit fiddly trying to use it on a small screen. But as with everything on this site, I hope it shows just how useful open data can be. If you do find a problem with it, have a request for an additional feature or just find it useful and want to let me know, then feel free to drop me an email at ads04r@ecs.soton.ac.uk.
Room Features updated
January 24, 2013
by Ash Smith
Over the last few weeks, Patrick has been exploring the university’s central data store looking for information on rooms and the features they contain. We’ve always had room features on data.southampton.ac.uk, but they were all generated from a single XML file given to Chris some years ago, and things change over time. So thanks to Pat’s fearless efforts investigating the central Oracle database, we now have a couple of scripts to pull not only room features, but booking information as well. A quick RDF generation script from me later, and we now have a method of ensuring the open data is as up to date as the university’s central database.
This is quite a big deal in my opinion – anyone planning a lecture or event can now view room information from the web and work out which rooms are suitable and available at the required time without having to phone Estates or walk across campus in the rain. Also, updating our data after such a long time is interesting for noting how things change over time; if nothing else, audio/visual technology is improving while chalk blackboards are definitely getting rarer!
New additions to data.southampton.ac.uk
October 15, 2012
by Ash Smith
 My name may not be familiar to people who follow this blog, so I’ll introduce myself first of all. I’m Ash, and I’m the new member of staff employed here at Southampton purely to manage the University’s linked open data. My official title, according to HR, is a ‘Data Management Specialist’, but Chris has been referring to me as a ‘Lodmaster’, which I think sounds far cooler. I used to work in ECS as a research fellow and did my PhD with Wendy Hall as my supervisor. I’m a lifelogger, and if you want some of my less thought-out comments, I can sometimes be found on Twitter as @DrAshSmith.
My name may not be familiar to people who follow this blog, so I’ll introduce myself first of all. I’m Ash, and I’m the new member of staff employed here at Southampton purely to manage the University’s linked open data. My official title, according to HR, is a ‘Data Management Specialist’, but Chris has been referring to me as a ‘Lodmaster’, which I think sounds far cooler. I used to work in ECS as a research fellow and did my PhD with Wendy Hall as my supervisor. I’m a lifelogger, and if you want some of my less thought-out comments, I can sometimes be found on Twitter as @DrAshSmith.
Apart from me, there are a few other additions to the site this week. Firstly, as users of the now-deprecated ECS EPrints system should be aware, the University has a central EPrints repository. So we now have a new regularly updated data set which maps users of the old system (and their papers) to the new system. The raw data is a massive list of owl:sameAs triples. On the subject of owl:sameAs, a new unofficial app that uses our data has been added to the Apps page of the site. SameAs.org is a service for finding equivalent URIs, and we now have a custom version of this service which looks for equivalent URIs according to our data only.
Easting & Northing
June 12, 2012
by Christopher Gutteridge
We’ve added a new dataset which adds Ordnance Survey style Easting and Northing data to everything which currently has a latitude and longitude (but only for items for which we are authoritative – University Buildings but not Bus-stops, basically.
If you get data from, say, http://data.southampton.ac.uk/building/59.rdf it now has Easting and Northing data in. I nicked the pattern from Ordinance Survey Postcode data documents.
Maybe this is useful, let us know if it is.
See the post on the Webteam Blog for the nitty gritty about how this works.
Launch of new University events calendar
May 29, 2012
by Christopher Gutteridge
The new University events calendar is now live and accessible via the current link http://www.events.soton.ac.uk/
The calendar was developed in conjunction with Electronics and Computer Sciences using Open Data as its foundation. It is automatically populated with events via RSS feeds from existing University websites, so minimal maintenance is required. Where a website does not have an RSS feed, staff can upload events manually via a SharePoint form http://www.southampton.ac.uk/submitevent/ This page also contains a list of the feeds currently used.
For queries of further information please email digital@soton.ac.ukn
Under the hood…
The data is aggregated once per hour into RDF from an assortment of RSS feeds, and a few stray websites, and a Sharepoint Calendar, then presented as a pretty javascript driven website.
The data is also uploaded every hour to the open data service, get the data.
The source code is available from github, and was paid for by the University Communications department, and mostly built by Colin Williams with some support from me.
Joining it up
The website uses the open data service data to let you filter by campus (it links building number to campus number to campus name), and filter by divisions of the university, get the name of buildings from their number and the homepages of the schools and faculties.
Thing is… the open data about university division homepages has not been maintained since we created the list a year ago. It was still mostly correct but some had moved and a many divisions had been created, or merged and so forth.
The exciting thing is that there’s now value to the comms dept. to maintain this information as it provides them value. This may sound minor, but it means that there’s an incentive to the “right people” to maintain this data, and that’s always been part of the model we’ve been striving for!
There’s still a lot of missing features; rss, ical etc. We’re working on that.
New and Automated Datasets
March 9, 2012
by Christopher Gutteridge
We’ve got two new datasets:
University Events Diary – this is aggregated once an hour from all over the university website and various other sources. It is going to be used to build a new university events website. Until then you can see the events on the pages for Faculties, Academic Units and Buildings. It (mostly) contains events which are open to the public.
SUSU Events – this is the same format, but contains events mostly restricted to our students. It’s pulled from their facebook page using the facebook API. Let me know if you want a copy of that script.
The Organisation Structure Dataset now pulls the structure and names from the university HR database every Sunday. The buildings occupied and homepages are still being hand maintained by me.
Updates and Automations
September 26, 2011
by Christopher Gutteridge
Org Updated
The “Org” dataset has been updated with data provided by our HR department on the new university structure, and the proper codes for everything. Where possible we’re using the two character alpha code (eg. FP for ECS) in the URI, but for the lower levels we’re using the full 10 charater code from the HR database, (eg. F7FP090000 for Web & Internet Science). This provides canonical IDs for all parts of the university, which is nice.
You can view the top levels on the organisation page. However, it now goes much deeper so I’ve added an option to let you view the entire org. tree.
Over the summer we’ve also added data on
- The location of student offices for each Faculty
- The location of the “deanery’ for each Faculty (although these usually are an entire floor, and our system doesn’t really do much with the concept of floors, yet)
- For faculties which have provided the data, a list of the buildings they ‘occupy’ (defined as controlling space in, rather than just having a member in that building). This has been provided by some faculties at the faculty level, and others at the Academic Unit level. We are happy to accept either. If we could complete this dataset it would be a very powerful resource.
- Where we can, we’ve added the homepage for that part of the University. We’ve not done this below the top two levels, but adding the data is very easy if people want it.
The spreadsheet in the get-the-data box on the organisation page is slightly unsual as I’ve set it to collect data we don’t show in the page. In addition to the URIs for the org. element and it’s parent element, and the label, it also includes a field for the code (FP or P2 or F5AF010000) — I figure that might be really useful for admin staff.
Update policy:
- Names of org. elements: This data belongs to HR and corrections should be sent to them. If they accpet it then I’ll update our data (please copy me the acceptance). Later, we’ll automatically source this data direct from their database.
- URLs for org. elements: data.southampton currently own this dataset, so it’s very easy to update. Just send us the correction to opendata@soton.ac.uk — I don’t anticipate much confusion so anyone is welcome to send us these.
- Space Occupied by org. element — This must be sent to us by an official admin for the group, unit or faculty concerned. If it’s a list for lots of org. elements, such as every group in a faculty, please get in tocuh as opendata@soton.ac.uk so we can send you a template spreadsheet to save us having to translate into the codes we use.
EPrints Automated
I should have done this ages ago, but the job got lost down the back of a sofa.
Every Sunday morning the EPrints datasets are now refreshed from the live archives.