Or ‘How I Learnt To Hate PHP‘.
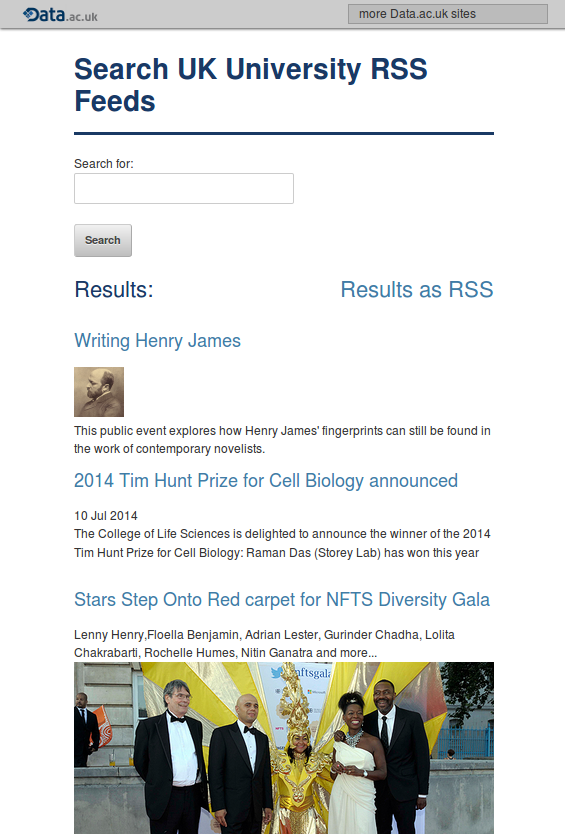 For the first few days as an intern my time was spent shadowing various people in iSolutions and learning some of the ropes. However, it wasn’t long before I was assigned my first project: using Observatory to collate the RSS feeds from the home pages of all the UK academic institutions. Such a website would help streamline access to data that is already out there – a centralised hub to search through, generating custom RSS feeds for data of interest, rather than having to manually check various sources.
For the first few days as an intern my time was spent shadowing various people in iSolutions and learning some of the ropes. However, it wasn’t long before I was assigned my first project: using Observatory to collate the RSS feeds from the home pages of all the UK academic institutions. Such a website would help streamline access to data that is already out there – a centralised hub to search through, generating custom RSS feeds for data of interest, rather than having to manually check various sources.
Before I go into the details, you can find the finished result here.
The rough plan was to pull the data from Observatory, parse it to retrieve the location of the RSS feeds, crawl across the feeds (dumping the relevant information into a database), create the ability to query said database, generate RSS feeds from the results, then put a nice shiny front-end on everything. The languages to be used were PHP, MySQL, HTML and CSS.
- Pulling the data:
- One of the first things I was told about PHP was that it has a function for absolutely everything. Absolutely. Everything. As a result this was a rather trivial task – one function to get the contents of a URL, one more to decode the returned object into JSON. It’s always nice when things start smoothly.
- Parsing the JSON:
- This was merely a case of checking there were values in certain bits of the arrays – plug in the key I want and see if anything comes back. If an RSS feed was there, add the relevant details to another array to be crawled over later.
- Crawling the feeds:
- For this task I was recommended LastRSS by Patrick – a very lightweight crawler that did all the necessary legwork. I had great success in using LastRSS, it was both very simple and very effective in its purpose. It is very forgiving of poorly formed RSS, which proved to be very useful.
- Dumping to a database:
- The information returned by the crawl was all inserted into a fairly simple MySQL database. In doing this I learnt a lot about using prepared statements in PHP – both making searching more efficient, and also helping to protect the underlying database against injections.
- Parsing the JSON, Round II:
- After running the crawl and dumping to the database it became apparent that there were some inconsistencies in the RSS feeds I was retrieving from the initial JSON data – some were full URLs, whereas some were just the suffix, e.g. ‘/rss’. A small fix was made to my initial parse – a check was done to see if the RSS URL was incomplete, if so the source URL was concatenated with the RSS URL.
- Crawling/Dumping, Round II:
- After this fix the crawl was run again and the data generated seemed much more complete. Excellent.
- Querying the Database:
- Now that everything for gathering the data was in place it was just a case of pulling out the information required. Once again, I utilised the magic that are prepared statements for this task. The ‘Post Title’ and ‘Post Description’ columns of the database were indexed, then search terms were entered into a simple LIKE query. This method returned adequate, but not ideal, results. Attempt number two was far more successful – using MATCH/AGAINST and IN NATURAL LANGUAGE MODE provided excellent results, if multiple terms were entered it would no longer just return entries containing all of them, but those containing both all and some. This also generated a ‘relevancy’ value, which the data could then be ordered on, providing the most relevant search results first (the initial query was ordered on post date). It was also necessary to make it so only results which happened in the past were returned, as some RSS posts seem to have been used to create events with future dates…
- Custom RSS feeds:
- Here I utilised a library called RSSWriter to create custom feeds – it was as simple as creating an object and putting the required data in. I love libraries.
- Shiny front-end:
- Now that all the back-end was functional, it was just a case of turning it into an actual web-page. A tiny bit of HTML writing, and CSS styling (once again from our good friend Observatory) led to a fairly presentable, and most importantly functional, product.
Overall I am happy with the current state of the product – it has some bugs to fix, and features to improve, but if I tell everyone that it’s currently in alpha then those things are expected and I’m let off the hook.
Some of the things that still need doing:
- There were some issues with character encoding – foreign characters caused issues within the database, and I believe the current fix for this has now caused issues with HTML characters (though why people have included HTML in their RSS descriptions is beyond me).
- The live server that the site is currently hosted on only has MySQL 5.0. IN NATURAL LANGUAGE MODE came in in MySQL 5.1. So we’re currently using the not-so-great LIKE search.
- A cron job needs setting up so that the parse/crawl/dump is done automatically.
I have learnt a lot about RSS, PHP and MySQL in this short project, so the whole learning part of the internship seems to be going well so far.
For those interested, you can find the GitHub for the project here.


Hi Ian,
If you’re new to PHP can I recommend you take a look at http://www.phptherightway.com/
Alex
This looks like a worthwhile and already-functional information integration project, that can also tell us about divergent publishing practices.
I was wondering about the RSS feeds in non-UK-English languages, like Welsh (for example http://www.llandrillo.ac.uk/cy/feed/), and whether that was modelled.
Also, whether ATOM feeds were looked at, and if so, did they present different integration/consistency problems/opportunities?