This response has been submitted to HESA in response to their consultation on open data.
This is a temporary location, the text will be moved to our consultations responses site in the next few days, and I’ll put a link in here instead.
Question 1
- Do you support HESA’s aim to make as much of our core data as possible available as open data?
- Please explain your answer
In general we support the aim to make data as open as possible providing the data is drawn only from the University’s signed off HESA returns—i.e., the data has been through rigorous quality control.
Question 2
- Do you agree with HESA’s assessment of its data sources regarding suitability to publish as open data (Annex A)?
- If not please elaborate on any areas in which you disagree
Yes, we agree with HESA’s assessment of the suitability of the data sources to publish as open data. It must not be possible to identify individual students or staff members from information published. It is vital that there is consultation and collaboration with HE institutions on the content of the data subsets released.
Question 3
Do you feel that the list of open data resources to be published in Annex B is comprehensive, or do you feel there are any other types of open data publication HESA should be planning?
Yes, we feel the list published in Annex B is comprehensive.
For linked-data purposes it would be very useful to provide mapping tables (“linksets”) from ID schemes used by HESA data to other common ID schemes. http://learning-provider.data.ac.uk/ currently provides a number of these “linksets” which could be polished and expanded. These reduce the costs to data-consumers wanting to join HESA data with other datasets.
Question 4
- Do you agree that it is important for HESA to publish meta-data as open data in addition to the data sets?
- What benefits will this deliver for users?
Yes, we feel the meta-data should be published—without this, data users will struggle to understand and analyse the data. We feel that the HESA data model meta-data should be released in the same time frame as the data sets—without this information it is likely that data users who are not familiar with HE may misinterpret the data and reach incorrect conclusions, generating unnecessary queries and work for HE institutions.
Question 5
- Do you feel that HESA’s aims on ODI certification are pitched at an appropriate level of ambition?
- If not please elaborate on the reasons for your answer
A cautious ‘yes’. There is a risk of spending limited budget on less important aspects in order to achieve certification.
Question 6
- Do you agree that Creative Commons Attribution 4.0 is the most appropriate open data licence for HESA to use?
- Please explain your answer
Yes, but for some datasets it may be desirable to make them even more open—e.g. not to require attribution at all. This should be considered for any data which is likely to be combined with data from dozens of sources or the most simple (non-statistical) parts of datasets, where attribution could impede use in some cases. For example simple lists of ID, label or linksets.
Question 7
Do you have any advice for HESA in establishing communications channels to open data communities and users?
HESA have very strong ties with HE institution administration teams, but less so with academics, students and developers. Attempts should be made to promote the existence and value of the newly opened data directly to researchers and developers (who may be able to provide surprising new uses), to make it easy for such people to report back new applications to HESA, and always to be asking “why aren’t you using our data”. In our experience, it’s often hard for an open data producer to see where small amounts of investment could remove an impediment of which they are not aware.
Question 8
- Do you think the list of proposed actions is appropriate and comprehensive?
- If not, are there other elements which should be considered?
In addition, we would encourage HESA to consider reviewing
http://learning-provider.data.ac.uk/ and http://opd.data.ac.uk/ — these are very low cost sites that we have produced for the benefit of the UK HE community. It may be appropriate for HESA to lift some of these ideas or build upon the work.
Question 9
Do you have any other general or specific comments about HESA’s proposed approach to open data?
The area where we have the most concern is the availability of data without any supporting context to aid interpretation. Raw data can result in the wrong assumptions being drawn and comparability between an institution from one year to the next, and between institutions within the sector, can be difficult. For example, the introduction of new accounting standards (FRS 102) for the 2015/16 year onwards has introduced significantly more volatility in a university’s financial results, which makes comparisons between years and with other universities difficult without a supporting narrative that explains the key factors impacting on those figures. This applies to all data sets. We think that HESA needs to ensure that the project addresses how this data can lead users to draw appropriate conclusions.
We are also concerned about how the data may be used commercially—at the moment consultants who market to us do not have access to our data; providing open access may generate a flood of firms writing to us to sell services and systems. A concern has also been raised that if data is going to be open it may impact the completion of the optional elements of returns; not completing these aspects of the returns may become a way to prevent the data becoming widely available.
We encourage HESA to make a clear plan for preservation and long-term access.
The University of Southampton has been very active in exploring the benefits of open data approaches for the UK HE sector. We have a comprehensive open data service covering many aspects of the university infrastructure. http://data.southampton.ac.uk . We founded data.ac.uk as a deliberately generic place to host data and linked data identifiers (URIs) so that they could be unchanged even if the hosting or sponsoring organisation changed, renamed or rebranded.
This policy could engage new and less-experienced software developers and other consumers but it shouldn’t be assumed that they have the same cultural background and training as those consuming HESA data historically. Clear guidance and easily noticed warnings will be required.
One unusual aspect for the Open Data community is that staff at universities may be subject to additional professional restrictions about how they can publish data from HESA, even if it has a CC-BY licence. This will need to be communicated clearly so nobody unwittingly breaks rules.
It is desirable to make datasets from multiple years compatible so that an investment in tools and services based on one year’s data gives value for several years. Changes to the data structure of datasets are inevitable but effort should be made to design dataset structures that can be extended in future years while still being compatible with tools developed to work with earlier years.
HESA is one of the pillars of data in UK HE. As such, HESA should work with the other data services in the sector to align identifiers as much as possible. This provides two important benefits. The first is the ability to join other datasets to the HESA data without expensive mapping exercises. The other is to provide an information infrastructure that other organisations can use for their own datasets.
All field definitions, terms and identity schemes used in the datasets and metadata should be available for other people to view in their entirety and reuse under a licence at least as open as, and compatible with, that of the dataset. Where possible international schemes should be used or mapping provided to reduce the costs of comparing and combining datasets from other providers both domestic and international. Where possible, and relevant, data terms and classes should use established data vocabularies such as the Organization Ontology https://www.w3.org/TR/vocab-org/. A listing of vocabularies in popular use in open data can be found at http://prefix.cc/popular/all.
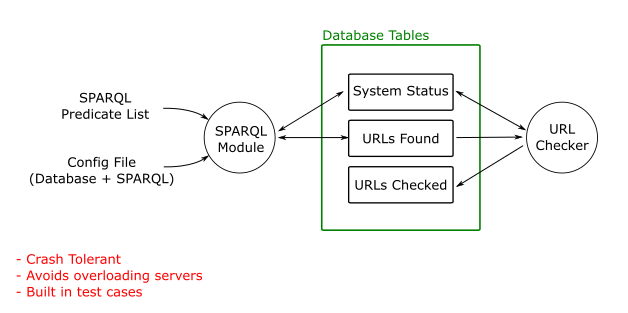
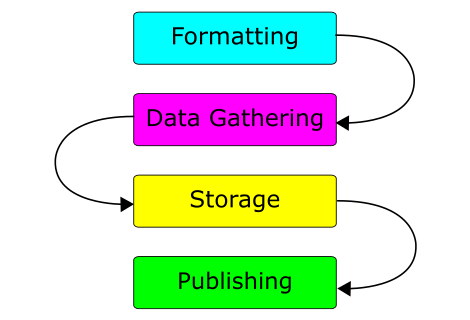
Much of the data HESA publishes needs to go through strict quality control. This data will probably only be published annually. There is other data which can be “self-certified” by an organisation, for example their current undergraduate admissions page or email address. This information may change out of sync with the annual publication process. We have successfully built a system to harvest such self-certified information and datasets http://opd.data.ac.uk/ and would encourage HESA to consider this as a route for keeping up to date with self-certified data. This route is also lower cost as it doesn’t require a constant formal relationship with every data provider (although HESA will have one anyhow).
A simple, but powerful example is this dataset http://opd.data.ac.uk/dataset/linkingyou, which is built nightly from open data from 32 HE organisations. This data may be valuable to HESA and its users, but can be “self-certified”—unlike statistical information, which requires quality control before publication.
Information on the process for correcting issues and errors should be included in the metadata for a dataset.
We would be interested in working further with HESA on this project.