I’ve spent this week reorganising the folders in My Documents. “But Callum!” you might say, “Isn’t that a complete waste of a week?”. Perhaps for some. In reality, I’ve been working towards creating an Open Data Pipeline.
Open Data Pipeline is a term I just created, and I think it refers to something like this:
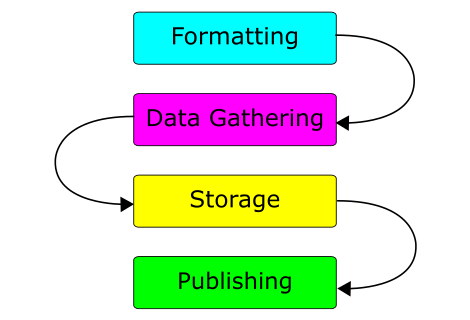
In this post, I’m going to outline the pipeline I’ve created so far and the lessons I’ve learned in making it.
The pipeline so far
So far, the pipeline has four key stages:
Gathering – This is gathering the raw data using a system. This could just be pen and paper. In my case, I’m using a homegrown tool called OpenGather. It’s a web application designed for gathering categorised open data. You can input data, record GPS locations and send the data for remote storage. This database then exports a CSV file.
Storage – This is the long-term storage for data. Currently, I’m using an Excel (or Calc) Workbook for text and numeric data. It has a sheet each for data gathered by the tool and for data I’ve had to enter by hand. A folder of images is kept for each category. For example, “Buildings” or “Portals”. Long term, the folder hierachy and exact data format still need work.
Processing – This is taking the stored data and converting it into a format ready for publishing. To process the output from OpenGather, I use another homegrown tool. Yet unnamed, it reformats the data as a CSV file, marking any missing data for completion. Optionally, it attempts to use timestamps to match up data with the images taken using the camera.
Publishing – This is the act of making the data available to the public. To do this, I hand a USB stick with the data on to Ash. Occasionally I have to copy CSV data to a Google Document. The rest of the open data service takes over from here!

One of the Excel sheets used for long term storage
With that said, here are some of the things to do and avoid when building a pipeline:
Things to do
- Use an appropriate set of input fields for each category – I originally had the fields “Timestamp, Tag, Category, Latitude, Longitude, Accuracy” for everything. I found that for some objects, such as Images, I could throw away the geo data. For others, I needed extra data I later had to enter by hand.
- Be consistent in your data gathering process – For example, knowing that an image is always taken after the data is entered is extremely useful. It can be used to later infer information you’ve forgotten, lost or never had.
- Keep a backup of your data – You never know when your tools will delete or corrupt an important file. Excel did this to me more than once!
- Be thorough in gathering your data – Gathering too much data and throwing it away is far easier than needing it and not having it.
- Challenge your assumptions and provide for corner case – I guarantee making assumptions about the properties of a data type will come back to bite you.
- Get some data up – Even if it’s just one entry, it’s a great feeling getting it hosted for the world to see.
- Process the data as a single, large batch – Removing the need to repeatedly process different chunks of data will save time in the long run.
Things to avoid
- Taking photos in many formats – Some cameras take both RAW and JPG. This makes storing the files and matching images to data entries that much harder. Use a single image format and convert it as you need it.
- Directly using Geolocation data – For most types of object, I’ve found GPS accuracy to be too low (6m radius at best). I used a clickable map to get accurate data, using the GPS to roughly centre it. If nothing else, precise data adds a level of professionalism.
- Using Excel for CSV files – If you do, format it all as “text”. Otherwise, Excel is fond of re-formatting your data to be less accurate when you save it back to CSV.
So where am I going from here?
My upcoming ideas for the OpenGather tool involve:
- Using different input fields for each data type. This should make processing the data more accurate.
- Provide the option to submit data to iSolutions via Serviceline. This should allow each contribution from students to be reviewed.
In the longer term, I’m looking to:
- Start work on an Open Data link validator. This tool will detect broken URIs and URLs, flagging them for correction.
- Start building maps of Union facilities ready for use during bunfight.


0 Responses
Stay in touch with the conversation, subscribe to the RSS feed for comments on this post.