Week 5 already? It feels like the time has flown by. This is a particularly interesting week for me, as Chris is away story-ing. I have plenty to do, but it all needs doing under my own steam. That’s why this is a fantastic time to talk about time management. More specifically, how woeful I am and how to improve.
Thoughts on Time
To begin, I want to talk about task lists. An easy-to-use task list has single-handedly made the biggest difference to my time management. It’s done that by ensuring I never forget a task. I can always see the tasks I have to do, prioritise them and set deadlines. By prioritising them, I can always work on the most important thing.
The trick to using a task list effectively is to put everything on it. Every little job, no matter how small, needs to go on it. It needs to be an authoritive list of everything that needs doing.
When the list contains everything, you can work purely off the contents of the list. You just pick off the most important task you can have time to work on and get to work.
My two biggest time management issues are tunnel vision and getting distracted. The former is where you get caught-up working on one thing. The mistake is not stepping back and asking “What’s the right thing to be working on?” periodically. As for getting distracted… it’s hard not to, in a lab filled with shiny objects and fantastic people. Hopefully, these will be solved in later blog post.
Work for the Week
This week, I’ll be mainly working on creating a SPARQL URL checker. This will build a database of all the URLs a SPARQL endpoint knows about (URLs in this context meaning website addresses, rather than RDF URIs). It will then launch requests to each of those URLs, reporting the status of each. The aim is to identify any broken links that need repairing.
Chris and I spent Friday planning the system, which should look something like this:
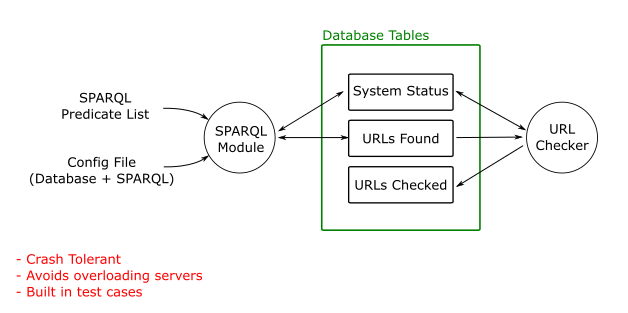
A high-level plan of SPARQL-Detective
The code will be available at https://www.github.com/Spoffy/SPARQL-Detective in the near future.
I’ll also be working to implement some of the changes to OpenGather I mentioned in my previous blog post. The main focus is to implement a schema for each type of data to be gathered.
PHP – Or as I now call it, “Interpreted C”
As promised, a short rant. So, this internship has been my first time working with PHP. I used it for the OpenGather tool, and up until now it hasn’t been so bad.
However, I have since been introduced to the joys of the cURL library. Here’s a short snippet to query a URL in cURL.
$curlHandle = curl_init($url); //Force it to use get requests curl_setopt($curlHandle, CURLOPT_HTTPGET, true); //Force a fresh connection for each request. Not sure if this is needed... curl_setopt($curlHandle, CURLOPT_FRESH_CONNECT, true); //Get Headers in case we need Location or other. curl_setopt($curlHandle, CURLOPT_HEADER, true); //Attempt to follow redirects curl_setopt($curlHandle, CURLOPT_FOLLOWLOCATION, true); //Do we care about SSL certificates when checking a link is broken? //...Possibly if there's SSL errors. V2. curl_setopt($curlHandle, CURLOPT_SSL_VERIFYPEER, false); //Don't actually care about the output... ob_start(); $result = curl_exec($curlHandle); ob_end_clean(); $link_status[$url] = curl_getinfo($curlHandle, CURLINFO_HTTP_CODE); curl_close($curlHandle);
Oh, sorry, did I say short? I lied. This bit of code summarises my thoughts on PHP perfectly. The code is verbose, unnecessarily so. It’s missing high level abstractions (You have to manually parse the returned string for header data). And it all somehow feels… clunky. Thankfully, at least memory management isn’t a problem.. right?
For comparison, here’s the same snippet in Python.
link_status[url] = urlopen(url).getcode()
….The joys of cURL!


Hi Callum,
The equivalent of your Python example in PHP is `file_get_contents`.
I’d recommend though using a third party library such as Guzzle (https://github.com/guzzle/guzzle) to make HTTP requests. Guzzle is very similar to Requests in Python.
I hope that helps,
Alex
Hi Alex,
Thanks for the suggestion! Unfortunately, “file_get_contents” won’t return the HTTP status code which is the data I’m after. I’ve tried “get_headers”, but that’s not asychronous nor particularly pleasant.
Guzzle looks pretty fantastic though (the use of promises for ASync in particular!).
Many thanks.
Callum