When hunting for something unrelated I discoved a very old MSWord file containing the documentation for “Jerome” which was the ECS publication database that I worked on before EPrints.
1999
In 1999 I was 23 and only graduated a couple of years. There was no Wikipedia and I didn’t know any librarians. Dublin Core existed but I didn’t hear about it, and it would have been far harder to discover its existance.
At the same time, Rob Tansley was working on EPrints v1. I didn’t like EPrints, mostly because it was a rival to Jerome, which I’d worked hard on, and there was a lot of pressure to replace Jerome with EPrints.
Then Rob got a new job and was off. I found out later the new job was starting D-Space, the main rival to EPrints over the years. I had the EPrints code foisted upon me to do minor tweaks to get v1.0 out of the door, specifically adding support for OAI 1.0 when it was finalised. It also used CSV version control which I’d learned about but never really used. 16 years later, and I feel nervous if my shopping list isn’t in git.
I ended up deciding to make a few more tweaks to the codebase of EPrints to make it more configurable and internationalisable. I made some great choices, and some poor ones ($session as a god object was one of my worst ever). Some of those were based on what I learned from creating and running “Jerome”. A very bright intern worked for a summer holiday to help refactor much of the code to be more configuable. He’s now Dr Mike Jewell and sits about 10m from my current desk. Our work became EPrints 2.0, which was far more configurable assuming you were happy to edit XML & Perl configuration files. Much later came EPrints 3 with many more contributors, and which cleaned up much of the internals and 3.1 which introduced far more friendly configuration tools for the admin.
Over it’s lifetime EPrints has enable many researchers easier access to research and that was the mission. I have no pride in successfully helping people gather metrics, no joy in the embargo feature, and don’t even like the ability to restrict downloads, but I have immense pride that in some way I’ve contributed to science and research and that all started for me with Jerome.
Here’s the documentation I dug up, I’ve left the spelling mistakes as they were at the time.
“Saint Jerome”
“Jerome” is a Publications Database for the ECS Department.
It has been implemented by Christopher Gutteridge.
Electronic support via: webmaster@ecs.soton.ac.uk
The ECS Publications database is called “St. Jerome” after a monk of the 4th century AD who worked for accurate translations of the Bible.
St. Jerome is the patron saint of scholars and librarians.
ECS Publications Database : Goals
- To improve the image of ECS
- To facilitate people finding details of our publications.
- To create a unified method for staff members and research groups to keep track of their publications.
- To aid creation of next Research Journal
- To aid the Performance Review and Research Exercise.
- To provide a one stop archive of all ECS Publications
Database Fields
Standard BibTex Fields
| BibTex Key BibTex type Author(s) Editor(s) Abstract |
Title
Book Title How Published Chapter Pages |
Journal
Number Number Publisher |
Organisation School Month Year Institution |
Additional Fields
| ISBN Number | ISSN Number | Performance Indicator | Project(s) |
Editor and Author field may have ECS members’ usernames associated to allow searching. This implicitly associates a record with the groups of its authors and editors.
Publication Store
The body of a publication may also be stored in the system.
Either as a single uploaded file from your terminal – eg PDF or Postscript.
Or as an HTML format page – the specified URL is captured from the web along with any images it needs.
Retrieveing Information
http://www.bib.ecs.soton.ac.uk
Records for a member of ECS
You may want to link to a page containing your records. For example, the page for Mark Nixon is:
/cgi-bin/people/msn
Records for a Research Group
To link to a page listing the publications for a specific group use:
/cgi-bin/group/mmrg
General Search
The current search allows the following fields:
| Free word search ECS ID Project ID Research Group |
BibTex type Words in Title Start and/or end year |
More options can be added to this if needed
BibTex
Search results and lists of papers for groups and people may be downloaded in BibTex format. The system will use the BibTex key it was given or generate one if that field was not filled in.
Records
While the list pages only provide a summary of each record, they also link to a page with all the information stored on that record.
Creating Records
2 Methods – “Wizard” or full page
Wizard Presents fields in ‘bite size’ numbers – about 4 to a page
Option of mini-wizards later, which don’t display all fields, for adding specific kinds of record.
Unlimited number of “Project” “Author” and “Editor” fields may be entered on a record. (Use the [More Projects] button)
Once the record is created you are given the option to associate an actual file with it
Upload from hard drive or URL if from URL grabs that page and images on it.
Modifying an Existing Record
From the HTML page for the record you may (permissions allowing):
- Delete Record
- Modify Record
- Clone Record
Cloning a record creates a new record based ont the current one. The fields of the record are all duplicated but a file associated with it is not.
Design of Publications Database
The system has been designed to make it easy to add more interfaces. For example, allowing data to be exported in different formats, and to synchronise the data with other databases.
The ‘back end’ of the system could be changed without an impact on the CGI interface.
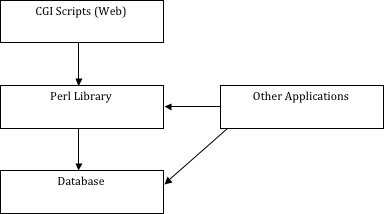
Security
Adding new records
Currently limited to ECS staff.
Individuals or other groups based on the Departmental Managers database (ecsinfo) can easily be added.
Modifying records
The person who submitted a record plus all those in ECS listed as an editor or an author may modify a record.
Viewing data
ALL records are world visible, however the uploaded body of the record (PDF/Postscript/whatever) may be restricted to ECS only or even just to the people who can modify the record. This is not as silly as it sounds as the system still provides a store for this information even if it’s not being shared.
Backups
- Whole machine backed up every working day
- SQL specifically dumped and backed up in addition to main system backup.


Yeesh, whenever I find something from my past I delete it quickly before I remember how bad I was at coding. It all started some years ago when I found an old PHP script (with a PHP3 extension) which started with the following line:
set_time_limit(0); // I’ve got a bubblesort and I’m not afraid to use it
*shudder*