This week I continued on my proof of concept project, and more specifically looked at ways of indexing the knowledge base articles in order to be able to search them and identify similar articles. There are many libraries and tools built for this, and one that I investigated early on was called gigablast. This system is built for linux, and integration with my .NET project was difficult. I decided instead to look into options native to .NET. The solution I found and integrated with my project is called Lucene.NET, and is an indexing tool originally written in Java, then later ported to C#. This tool indexes items and saves this index to disk where it can then be read at a later time by any application using Lucene with access to that disk space.
Once I had indexed the knowledge base, I then began to investigate other features of Lucene, such as the search features. I created a search function that uses Lucene to search the indexed articles, looking for articles containing exact matches to the search term. I then extended this to use fuzzy queries, where matches that are a set number of edits away from the search term are also returned. For example, if someone were to search VPM instead of VPN, that would count as being one edit difference and therefore with a fuzzy query allowing at least one edit difference a search for VPM would still match with VPN. This is a really useful feature to have, especially with less technical users who may misspell important terms. Once I’d investigated with different search features, I then looked into adding further functionality to my web application by providing links to related articles at the bottom of article pages. This was interesting to play around with, comparing similarities in the title and in the main body of text, with both a standard analyzer and a snowball analyzer, comparing which resulted in more relevant articles being identified. The standard analyzer identifies terms and counts their frequency. A snowball analyzer does the same, only it allows for stemming of words, so the terms print, prints, printing, and printers are all identified as being the same word. There are drawbacks to the snowball analyzer, also identifying terms like organization and organs as being the same, so allowing for more mismatches in some cases. Despite this drawback, I found the snowball analyzer to do a better job in most cases at identifying similar articles, and just comparing titles to give more obviously similar results, whereas comparing the main body of text sometimes returned results that weren’t immediately obviously similar to the given article.
The next step for my web application was to make it look professional enough to possible be an outward facing application by applying the university branding rules to it. I was given a link to the new university branding guide, https://www.southampton.ac.uk/brand/. This website lists in detail how to brand posters, choose fonts, and even how to advertise the university on the side of a mini-bus, but very little on how to create a university of southampton website. I decided, instead, to use the source code of the branding website as a kind of template, and to try to integrate it with my existing web application. This proved more difficult than I originally anticipated as the website wasn’t designed to be pulled apart and reused for a different purpose, but eventually I ended up with a website that looked vaguely professional. There are still a few small bugs such as the navigation menu moving up half a centimetre when you hover over it, and the title shifting downwards if you hover over the breadcrumb links just above it, but all in all the web application is starting to look more clean and professional.
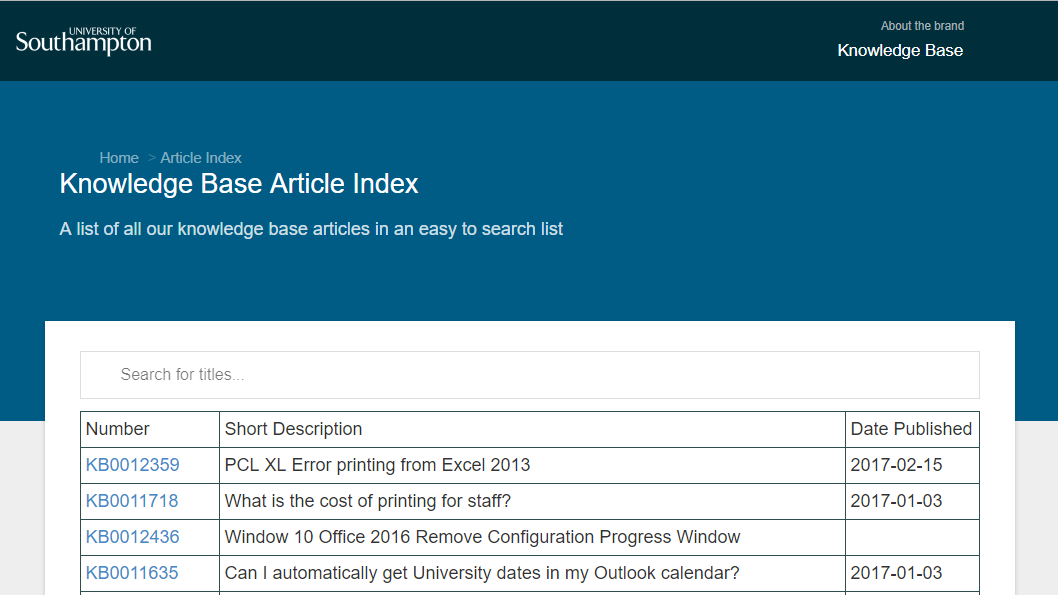
The next steps are to iron out those little visual bugs, probably moving the breadcrumb links as they’re not in a very aesthetically pleasing place at the moment, and ensuring this style works for article pages too. From there, I’d like to get other people’s opinions of the website, to see if they find it more or less useful than the existing knowledge base browser, and to work out how it can be further improved.


0 Responses
Stay in touch with the conversation, subscribe to the RSS feed for comments on this post.