“From a starting point of little knowledge and still less understanding, the KeepIt project has demonstrated that digital preservation need not be scary. The secret is to take small steps; to set preservation planning within the bigger institutional context; and to engage stakeholders.”
Near the start of the KeepIt project, Steve Hitchcock, our project manager, asked the exemplar repository managers to come up with preservation objectives for each of their repositories. NECTAR’s objectives were four-fold:
- Objective 1: to define the preservation needs of all file types and formats held in NECTAR (now and in the foreseeable future).
- Objective 2: to have procedures and tools to support the preservation needs identified in objective 1.
- Objective 3: to have documentation to inform and support NECTAR stakeholders.
- Objective 4: repository staff and others with collection management responsibility for the IR to receive training and ongoing support.
Reflecting now on what we have done in the KeepIt project – what we have learned and the benefits we have derived from the project – it is clear that as far as NECTAR is concerned, we have gone a long way toward achieving our goals.
Early discussions between Steve and the project team identified several areas of common interest. This list, combined with a liberal helping of Steve’s expertise, led to the development of the KeepIt course. Others have written extensively about the course in this blog, so I’ll restrict myself now to the impact which it has had on myself, NECTAR and The University of Northampton.
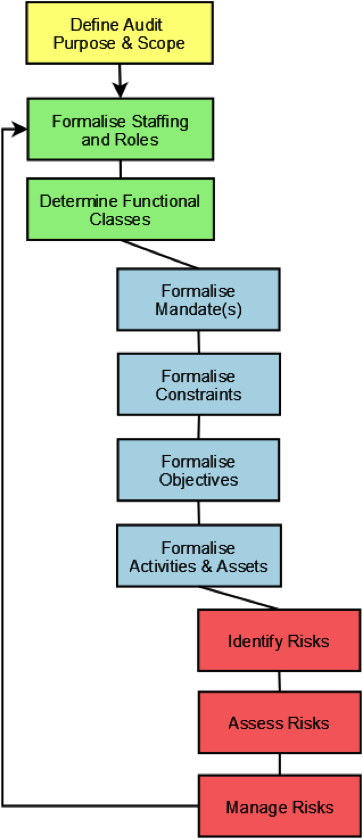
Module 1, on organisational issues, introduced us to the Data Asset Framework (DAF) and the AIDA toolkit. Both of these appealed as tools for auditing different aspects of the institution’s state of readiness for preservation. At Northampton, we decided to have a go with the DAF tool and I have blogged already on this. In the NECTAR team we have always prided ourselves on supplying what is most wanted and most benefits our research community and we felt that the DAF methodology would not only provide us with the evidence we would need to produce an appropriate preservation plan, it would also highlight gaps in current service provision and opportunities for improving the university’s research environment. This proved to be the case.
“A major report from our DAF project is shortly to be presented to the university’s Research Committee and nine recommendations will be made.”
Module 2, which dealt with the costs of preservation, covered a further two models: Keeping Research Data Safe (KRDS2) and LIFE3. With Neil Beagrie we looked at the potential benefits of keeping research data in a repository (both direct and indirect; near term and long term; private and public). In theory, these are indisputable: time saved; transparency; opportunities for re-use and re-purposing of data; increased visibility and citation… and so on. But in practice there is great resistance among researchers to the idea of putting data into a repository. Our DAF project at Northampton was clear on this. Research datasets contain sensitive information; they represent a lot of effort on the part of researchers; they aren’t designed for communal use – all of these deter researchers from providing open access to their research data.
My colleague, Philip Thornborow, our Collections and Learning Resources Manager, was particularly interested in the LIFE3 model. In Philip’s words (just after attending module 2):
We have a lecturer who has located some content in another library that he believes it would be beneficial to digitise. Neither the lecturer nor my university have much experience in estimating the full economic cost of such a project. During the demonstration of LIFE at the [KeepIt] training programme, it became immediately obvious to me that this tool was just what we need. The experience of the British Library and the other case studies they have used provides real data which can be used in the model. As we worked through the model it also became obvious that all the assumptions are clearly labelled, so we could vary the values in line with our local situation and gain an idea of whether our proposed bid was viable.
We are looking forward to testing LIFE, and in particular are interested in testing Brian Hole’s (LIFE3 project manager) comment that it can be used in reverse, so to speak. In other words, if JISC gave us £x what would we be able to achieve. I am severely averse to wheel reinvention, so any tool that can allow us to stand on the shoulders of giants, as the man in the BL courtyard said, gets my vote.
The LIFE3 tool wasn’t at that stage quite ready for public use, so Philip wasn’t able to take advantage of it then. Events have now moved on and his immediate need for the tool has passed. However, should he be required to provide costs for a future digitisation project, he remains interested in using LIFE3.
With a change of venue (from Southampton to London) came a change of emphasis in Module 3 of the KeepIt course. We started to look at file formats and to consider the significant characteristics of digital objects. Based on the PRONOM list of format risks (ubiquity; support; stability, lossiness etc), Steve asked us to evaluate pairs of file formats (for example, MS Word vs PDF) and to score a point for the winner in each risk category. We then had to come up with a reason why we might not choose the higher scoring file format for the repository. The subsequent discussion was fascinating since it clearly demonstrated that not all risks are equal, and that there is no consensus, even among the better informed, on the best file formats to preserve. So perhaps the repository manager can be forgiven for sometimes being uncertain and a little confused?
For the rest of the day we looked at signifcant properties with Stephen Grace and at preservation metadata and provenance with Steve Hitchcock. In the exercises that accompanied these sessions we were once again forced to think hard about the real issues in preservation and how the theory could be put into practice.
“The combination of EPrints and PLATO tools for the first time puts real preservation action within the grasp of repository managers.”
Module 4, the only two day module, promised to be the one where we got down to the nitty gritty of practising preservation. Covering the new EPrints storage and preservation apps, and their interaction with the PLATO preservation planning tool, we had two days to learn how to develop a specific preservation plan for our own repositories. The combination of EPrints and PLATO tools for the first time puts real preservation action within the grasp of inexpert repository managers. In a test environment we were able to conduct risk analysis within the repository itself, create and test preservation plans based on our own requirements, and import those plans back into EPrints.
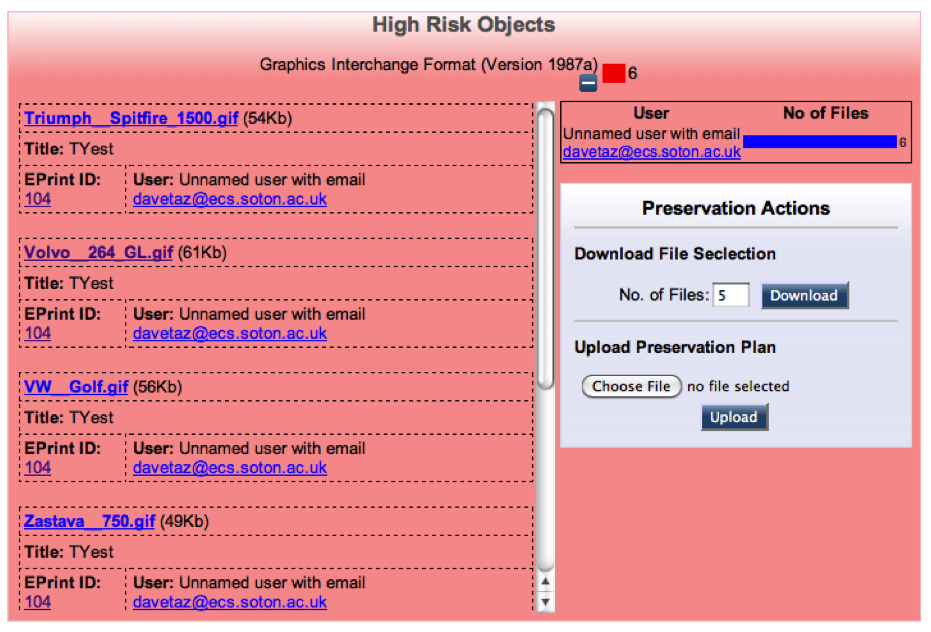
Since module 4, the good folk from EPrints Services have upgraded NECTAR to version 3.2.4 of EPrints and Dave Tarrant has installed the preservation plugins. We now know that nearly all of our files are versions of PDF and MS Word formats, with a sprinkling of XML, plain text and others. None are currently deemed to be at risk. We will now need to monitor this, to be sure that NECTAR content does not fall into a high risk category. At that stage we will find out whether the training provided in module 4 translates into effective action in the repository.
“We now have the knowledge and confidence to implement other preservation tools as needed.”
The fifth and final module considered aspects of trust in data management. We looked at tools for assessing trustworthy repositories, specifically TRAC and DRAMBORA. A couple of the course attendees (LSE and UAL) have since adopted DRAMBORA to good effect, and it certainly seems to do the business with regard to identifying, assessing, managing and mitigating risks to the repository. I can see that the use of DRAMBORA would provide more than just a risk assessment for the repository, it would produce considerable evidence to inform other institutional policies and procedures. The drawback is that we’re told it takes approximately 40 hours of work to complete the tool. Perhaps, like the two institutions above, here at Northampton we can find a way to use the tool more selectively.
Of course the KeepIt course hasn’t provided the only learning opportunity in the project. The regular meetings between Steve, Dave and the other exemplars have given us the chance to share experiences and to learn from each other. The repository community as a whole has always been mutually supportive – a culture fostered by the huge amount of funding and support from the JISC – so the good relationships between project members and course participants comes as no surprise.
“There is a risk that new knowledge is vested in one person. By involving colleagues I believe that we have broadened both interest in digital preservation and the impact of the project.”
So to return to our progress against the NECTAR objectives…
- Objective 1: to define the preservation needs of all file types and formats held in NECTAR (now and in the foreseeable future).
We have identified all file formats in NECTAR and established that none are currently at risk. We have undertaken a university-wide research data project using the DAF methodology. This has not only highlighted the data management practices of researchers, but also supplied us with valuable information about new file types that might be deposited in NECTAR in the future. - Objective 2: to have procedures and tools to support the preservation needs identified in objective 1.
NECTAR has been upgraded to version 3.2.4 and the EPrints preservation plugins has been installed. We now have the knowledge and confidence to implement other preservation tools as needed. - Objective 3: to have documentation to inform and support NECTAR stakeholders.
A major report from the DAF project is shortly to be presented to the university’s Research Committee and nine recommendations will be made. These include the creation of a data management policy for the university, clarification of the university’s position on data ownership, implementation of a programme of training on data management, and provision of online advice and guidance. It is hoped that this will raise the profile of records management in the institution and therefore have a benefit well beyond the relatively narrow field of research data. - Objective 4: repository staff and others with collection management responsibility for the IR to receive training and ongoing support.
The University of Northampton was fortunate in that not only was I, as repository manager, able to attend all five modules of the KeepIt course, but also I was able to bring along colleagues with a professional interest in each area. Thus our Collections and Learning Resources manager attended modules 1 and 2; our metadata specialist participated in module 3 and our NECTAR technical specialist attended module 4. There is a risk in a project such as this that new knowledge is vested in the one person with commitment to the project. By involving colleagues in the course I believe that we have broadened both interest in digital preservation and the impact of the project.







Recent Comments