KeepIt course module 4, Southampton, 18-19 March 2010
Tools this module: Plato, EPrints preservation apps
Tags Find out more about: this module KeepIt course 4, the full KeepIt course
Presentations and tutorial exercises course 4 (source files)
We continue our journey through the KeepIt course modules, adding commentary and context to the core materials for those who want to follow and apply the course at their own speed.
Module 4 is the penultimate module, and in some ways the culmination of the course – certainly it is the culmination of modules 3 and 4 and our approach to put preservation in the repository interface.
[slideshare id=3561165&doc=keepit-course4-intro-100326045654-phpapp01]
We’ve seen in courses 1 and 2 that digital preservation should be built into general information management – institutional policy and costings – but there’s an area that differentiates digital preservation, it’s somewhat technical and concerns file format characteristics. We learned about those characteristics in the previous module, KeepIt course 3.
In this module we will be using another tool, Plato, to create a preservation plan to manage file format characteristics, and applying this to files in a repository based on EPrints. The PLANETS project provided opportunities to learn about and practice with Plato, and EPrints offers regular training courses some of which will feature preservation, but this course module, and its final live incarnation, is the only place to put these pieces together. Once again we have top class presenters, who designed and built the tools you will be using.
Putting it in the interface: the importance of a familiar workspace

“75 million people already own iPod Touches and iPhones. That's all people who already know how to use the iPad.”
Apple recently launched a new machine – the iPad. It provoked differing opinions, from ‘can’t wait to use’ to ‘not revolutionary, just a bigger iPhone’. Why expect another revolution so soon? The key is the familiarity of the interface: “That’s all people who already know how to use the iPad”, said Steve Jobs, in perhaps the line that epitomised Apple’s design approach to the interface of the new device.
EPrints is not Apple, but it is attempting to put preservation in the repository interface, to enable tasks to be accomplished in a familiar working environment.
First, the previous module was a primer for this one, so a quick recap might help. We began with preservation workflow (slide 7). This will underpin our work in this module. We looked at the two ends of the workflow – finding out what we have (identification), and considering the type of preservation actions we may have to take (if any). We recognised risk as an area we will wish to control and moderate.
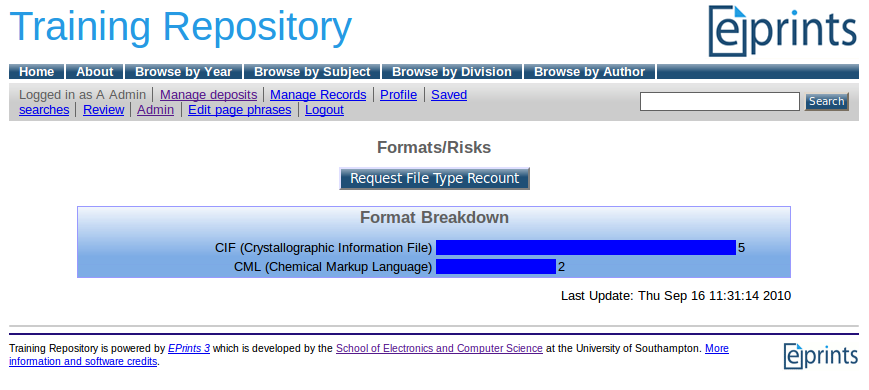
As an example we looked at the broad risks (slide 8) associated with some formats we identified in a typical repository format profile. Our teams compared and rated some familiar formats (slide 9). But note, we also came up with reasons why our ‘winning’ formats might not be the best choice in all situations.
We next looked at significant properties using the F-B-S engineering design framework (slide 13):
- Function-the purpose of the design
- Structure-of the designated digital object
- Behaviour-what a user wants from the object
In this way we aim to identify and understand the critical characteristics of an object that we seek to preserve, recognising that it’s not just what you preserve but how you preserve it that can affect its use.
We did an exercise to analyse the structure of emails (slide 14), where we were seeking to identify the behaviours required of the structural elements of an email (slide 15), and then classified these in five high-level categories (slide 16). A second exercise revealed that the expected behaviours of our email can be different depending on the user (slide 17).
In two rapid sessions we looked at two means to document these characteristics (slide 19):
- PREMIS
- Open Provenance Model
Not forgetting we began module 3 with a simple numbers exercise to show why it matters to document the significant characteristics and history of objects: numbers can change, features can change, information can change whenever it is transmitted and transcribed. Unless you are careful, you will not end up with the information you started with (slide 21).
There we have it, module 3 in a single slide (slide 22).
Digital preservation fundamentals: a recap
Now we will put it all to work in a repository. First, Andreas Rauber and Hannes Kulovits from the Vienna University of Technology will answer the question Why do we need digital preservation? This broad recap of digital preservation fundamentals will be familiar to many, but Rauber and Kulovits are skilled presenters and held KeepIt course particpants rapt.
[slideshare id=3561267&doc=plato-eprints-intro-100326051510-phpapp02]
What follows in this module, KeepIt course 4, is:
- Discover support for large-scale storage in EPrints (version 3.2) – go here next if you wish to follow this course module in the order of presentation
- Create a test set of data in our training repositories to investigate how we can manage format risk with EPrints
- The output of this stage we will take forward to create a preservation plan in Plato
- Finally, we will enact that plan back in our EPrints repository
Although we are using training repositories based on EPrints, we expect similar approaches to become available for other repository softwares.





Recent Comments