
LeapIn.it will allow people to “leap in” to rooms based around niche interests simply by scanning barcodes (or QR-codes) that may be found on relevant material (such as books and posters). However, it is reasonable to expect that one subject may have multiple barcodes. For example, the DVD and Bluray releases of the film Inception may have different barcodes. In this case, there will be two rooms for the same topic.
One solution may be to simply introduce some way to indicate duplicate rooms, much like the notion of “sameAs” within Semantic Web research. However, this presents two problems. First, who mark the duplicates? A person would need to know about both rooms in order to do so. Second, it may be unclear if two rooms should be considered “duplicates”. For example, what is to say that the rooms above (the Inception DVD and Bluray rooms) are not about their the film’s release on the respective mediums? Due to the differing contexts in which the users first entered the rooms, the rooms may be about subtly different things.
Still, a user may benefit from viewing the content of similar rooms, and we wish to avoid massive fragmentation of users across different rooms about similar subjects. Therefore, we propose to “link” together similar rooms using clustering algorithms.
Clustering
To cluster rooms, we first need to understand what each room is about. We could infer this from the original scanned source (i.e., the barcode or QR-code), however this may not be dereferencable to a particular subject (e.g, a barcode just decodes to a number). Alternatively, we can “learn” what the subject of a room is from the content that has been posted within the room. This would also present challenges when trying to understand the content of rich media, such as pictures and videos. Assuming we use the latter process on just textual content within the room, we can plot the rooms within a vector space.
The vector space is a multi-dimensional space, where each dimension is a general subject (for example, action, news, tools). Each room has a value within each dimension, thereby placing similar rooms together in the vector space, as shown in the illustration below.
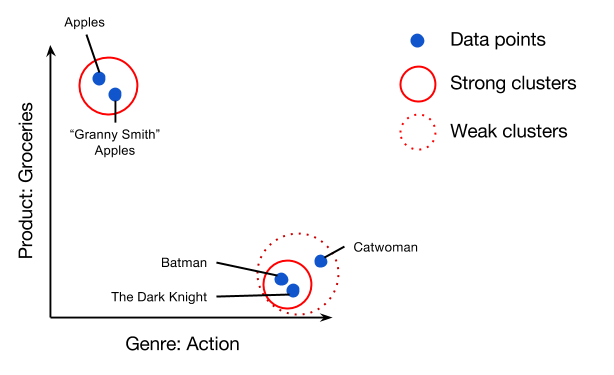
We can then cluster similar rooms by looking at which rooms are closest together. For the user, we may provide links to similar rooms, or simply post content from other rooms in a peripheral layer.







Please comment with your real name using good manners.