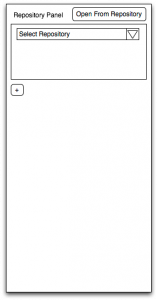
Sketch of Word author panel: 1, select repository for deposit
Conformance, level 0, level 3, process interaction, addin, plugin, CRUD. These are not all terms we typically associate with repository deposit, but they are key to understanding the DepositMO project.
My mother’s preference for flat-pack kitchens and furniture, admittedly financially motivated, gave me a lifelong aversion to self-assembly instructions. I prefer the articles finished by craftsmen.
So it was with some trepidation that I came to be reminded of this as I – until recently, the errant project manager for DepositMO, a project seeking to connect repository deposit with popular authoring applications – reassessed the documented work to date of the project and came across this array of terms.
One of the principal architects of this project is Dave Tarrant. I have worked with Dave for some years, so I am well aware that his approach – part vision, part inspiration, part technical ability, part technical audacity – does not always immediately or easily lend itself to simple interpretation. Thus we have to try and construct a view of the piece for ourselves using the information available, only to find later that the craftsman version was there all along.
For now, with DepositMO we want to understand the story so far. Here goes at telling this story, noting that it is an early-stage work-in-progress.
Embedding repository processes into the authoring environment
The essential idea of the project is to motivate more content to be deposited in open access institutional repositories by creating a deposit interface for the tools that authors use to create their content. By some margin these tend to be office applications – word processors and spreadsheets, for example – notably the suite of such applications produced by Microsoft.
One simple approach is for the ubiquitous ‘save’ and ‘save as’ functions in these applications to connect with repositories in the same way they currently save content to a local hard disc, on the user’s personal computer. This is CRUD – Create, Retrieve (or Read), Update and Delete – the approach described in an earlier blog post. Although CRUD is not new, it represents a new approach to repository deposit.
In that post we promised more on the practical implications of this approach, so here it is.
Typically, to deposit content in a repository an author will find the repository in which they wish to deposit, where they have a login, access a deposit Web form presented by the repository, fill in the necessary metadata and instruct the repository to upload the content, thereby creating a record linked to the content.
Is this process flexible enough for authors, given the multiple repositories and types of repository available now where they may wish, or be required, to deposit?
Is this process too difficult for authors? More specifically, does it take too long? While it has been shown that the deposit time can reduce to a few minutes for regular repository depositors, slow deposit seems to be a perennial problem, to the extent that most repository deposit now seems to be mediated by administrators. While this can work for relatively low levels of deposit, it is not clear it will scale with anticipated repository growth, certainly not for data and other types of resources now being collected in institutional repositories.
There is also the problem of a disconnect. This can be seen to begin with the disconnect between applications and repository, and is extended by deposit mediation. Thus the real disconnect is between the author and the repository.
Four layer conformance model
“Based on this conformance model, it ought to be possible for new platforms to adopt this approach to repository deposit, starting at level 0 and working upwards.”
From this point it becomes more technical. We have various author tools and we want to connect content created by authors using these tools with at least two types of repository, in this case DSpace and EPrints. Development will involve working with the author tools, the author’s computing desktop and operating system as well as the repositories, so to coordinate this we have a conformance model, currently with four layers.
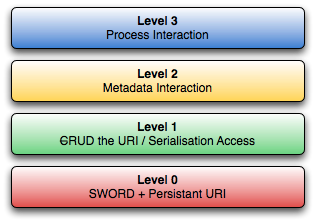
DepositMO four-layer conformance model
At the lowest level 0 we start with SWORD. This seems reasonable; it’s in the name Simple Web-service Offering Repository Deposit, it’s established and becoming widely used. We noted previously that further work on SWORD is needed, probably leading towards v2.0, to support full CRUD. For now we can use the current version 1.3 with one proviso, that the identifier <atom:id> in the return receipt MUST BE a persistent URI by which the object can be re-located. Thus Level 0 covers the current deposit procedure as supported by SWORD 1.3 with the added specification on what the receipt must contain.
If level 0 is the C in CRUD, level 1 covers the RUD. Having deposited an item we want to Retrieve it for further work, or retrieve it in some other form, or we want to retrieve information about the item, all from the URI specified in level 0. These different forms of the object might be called ‘serialisations’, for example, RSS and atom feeds used for current awareness services are serialisations. We can envisage other types of serialisation containing many varied items of metadata pertaining to that item such as current status (in the publishing lifecycle), number of views, downloads, citations, etc. Similarly, Update and Delete can now be supported by PUT/POST to the URI from level 0.
To support improved serialisations in one of the DepositMO repository platforms, an app store following the model of Apple, the EPrints Bazaar, is helping to abstract many of the current serialisation formats from the core EPrints code, so these can be updated more easily, and new ones added.
One of the reasons for slow repository deposit might be the degree of metadata required to describe the object being deposited. Ultimately this is down to the design of the deposit interface by individual repositories. To an extent this can be ameliorated by SWORD and some automated capture of data from the object, but in the deposit process there still has to be scope to collect additional data required by the repository or to improve metadata. This is the focus of level 2 in the conformance model.
Not only does this require a forms-based process interacting with the repository, it gets more complex when more than one repository is involved, such as multiple repository deposit. As we have seen, supporting multiple deposit is one of the key goals of DepositMO. Typically multi-repository deposit requires a depositor to interact individually with each repository, filling in the same metadata for each manually before being able to deposit, thus taking even more time with duplicate data entry. Clearly this is not ideal. Level 2 conformance is thus not only about allowing single click multi-deposit/update/delete, but about exposing the repository metadata requirements in the client application (using the client’s familiar interface) and hiding duplicate data entry. If the same metadata item (e.g. Title, Authors, Abstract) is requested by both repositories then it is only asked for once.
Where level 2 involves interaction between repository and user, level 3 enables the repository to interact with client applications. Typical operations might include format conversion or feature extraction. There could be many potential applications. This is the more ambitious end of the proposed implementation, and it may not be possible to implement this fully within the project timescale.
Currently this model is being fleshed out in technical documentation aimed at the respective developers. Videos showing early versions of some of these processes in action have been produced, and we will present those in another post.
Based on this conformance model, it ought to be possible for new platforms to adopt this approach to repository deposit, starting at level 0 and working upwards.
Emerging user interface
So that’s the functional description of the features we believe are required to support repository deposit directly from authoring applications. How do we present this to authors? There are services in Microsoft Office applications that could be used for this, but for flexibility and scope we anticipate that initially this might be better served by a separate interface, the author panel. The functionality of this panel has been sketched progressively to reflect the layered model, starting with the basic version, panel 1, that appears at the head of this blog post, through to the more complete version below.
Thus we can see in panel 1 the facility for the author first to select the required repository for deposit. Alternatively, if work is to be done on an existing document, that can be opened from the repository. By panel 4 we can begin to see support for multi-repository deposit.
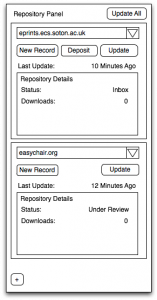
Sketch of Word author panel: 4, Full functions, with example of multi-repository deposit
Clearly these are sketches, and many issues remain to be resolved. For example, synchronisation between repositories where editorial buffers moderate deposit – in which case the individual repository Update buttons will take precedence over the Update All button. From an interface perspective, how to present lists of an author’s past papers for updating is another challenge.
It’s exciting designing new features for services that you really believe in. Might these prove a tipping point in spurring wider usage? Could do, but we don’t know yet. We do know that much remains to be done to make all this work optimally for the typical user.





 Enter SWORD, for it was suggested that this be the mechanism for sharing deposit and logins in this case. It turns out that the organisation developing SWORD has a
Enter SWORD, for it was suggested that this be the mechanism for sharing deposit and logins in this case. It turns out that the organisation developing SWORD has a 



Recent Comments