Archive for category Technical Details
Functionalities and Requirements
Posted by steiakakis in Technical Details on May 6, 2012
Register
| # | Requirement | Description |
| 1 | Required fields | Username, Password, 3 Secret Questions, 3 Secret Answers |
| 2 | User Verification | Insert password twice.
Acceptance of Terms and Conditions. |
Login
| # | Requirement | Description |
| 3 | User Details | Username and password to gain access |
| 4 | Password Retrieval | A user can retrieve his password if he provide the correct answers to secret questions |
Edit Profile
| # | Requirement | Description |
| 5 | User Details | A user can edit his personal details providing all the required fields. |
Add Supporter
| # | Requirement | Description |
| 6 | View Supporters list | A user can add another user to his supporters list. |
Support Requests
| # | Requirement | Description |
| 7 | View Support requests list | A user can view his support request list. He can accept or reject a request from another user. |
View Supports list
| # | Requirement | Description |
| 8 | View Supports list | A user can view his supports list which contains all the users that he supports. |
Sent Message
| # | Requirement | Description |
| 9 | Create new message | A user can send a personal message to another user. The receiver can accept or decline this message. If he accepts the communication from a user, that user is inserted on his trust list. |
Add to trust list
| # | Requirement | Description |
| 10 | Add a user to support list | A user can view his trust list that contains the users that he trusts to communicate with. |
Add to block list
| # | Requirement | Description |
| 11 | Add a user to block list | A user can view his block list that contains the users that he does not want to receive messages from. |
Search
| # | Requirement | Description |
| 12 | Search for a topic | A user can search for his desired topic using hashtags. |
Save Search
| # | Requirement | Description |
| 13 | Save a specific search | A user can save his favourites search gaining easier navigation. |
Upload Picture
| # | Requirement | Description |
| 14 | Upload a profile picture | A user can upload a picture and store it in his profile. He can also delete that picture. |
Create new topic
| # | Requirement | Description |
| 15 | Create new topic | A user can create a new topic of his interest using the provided form. The topic needs a title and some hashtags in order to be categorized. |
Comment a topic
| # | Requirement | Description |
| 16 | Comment on a topic | A user can create a new comment under a topic or another comment. |
Hosting on I2P
Posted by drakopoulos in Technical Details on May 3, 2012
The default install of I2P comes with a Jetty web daemom, so starting up the eepsite is actually incredible easy. On the router console homepage, in the left hand bar there is a link to the I2PTunnel under the heading I2P Internals.
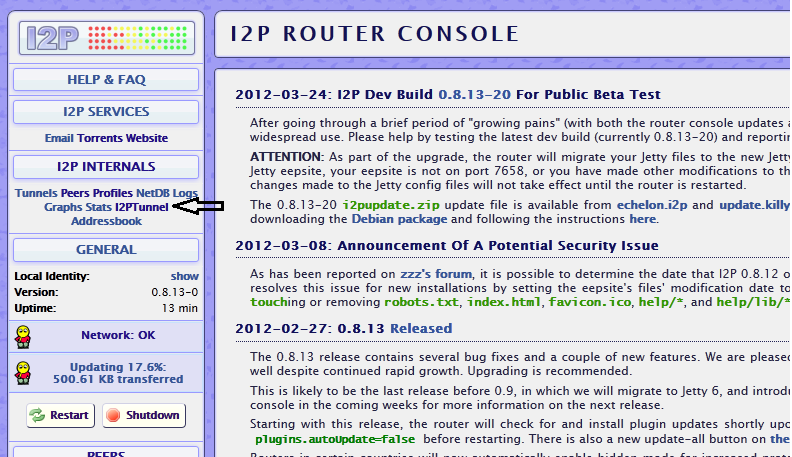
Once inside, in the I2P Server Tunnels section, you will see the default eepsite. Click the start button, and wait for it to start up.
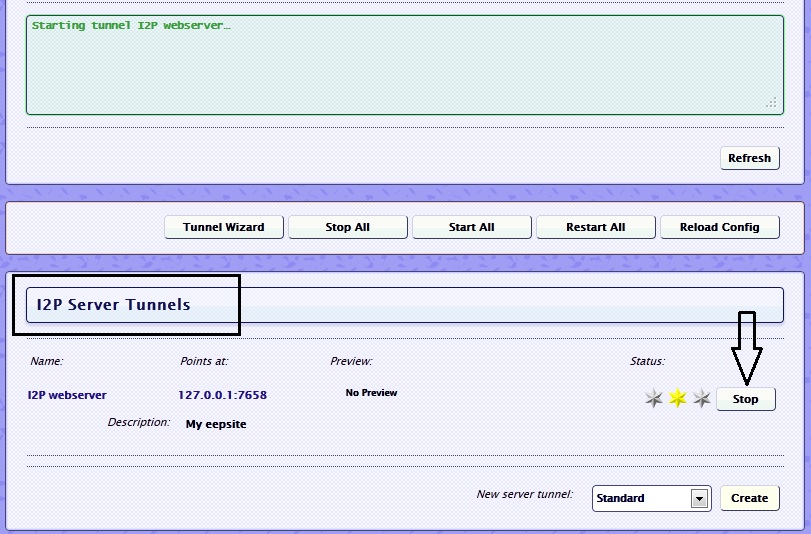
On Windows, at this location: C:\Program Files\i2p\eepsite is where you will find the index.html file of the eepsite. There are some redirect to help instructions in the file, once those are deleted things are good to go.
Of course, the destination of the eepsite is on the local host and it will be difficult for other people to find because it doesn’t have a name and they don’t have your really long Base64 key. You could just tell people that really long key, but thankfully I2P has an address book and several easy ways to tell people about your eepsite.
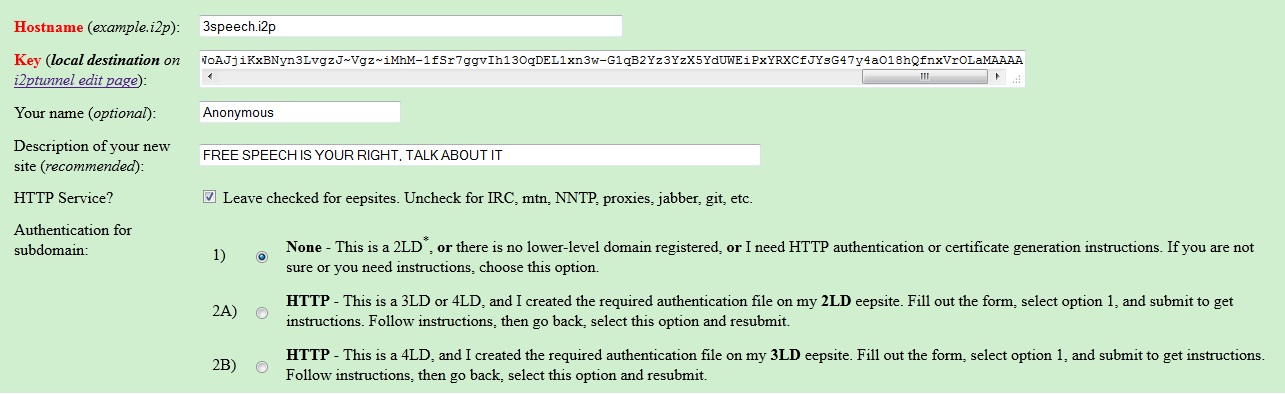
First, enter the new name of the eepsite on the eepsite i2ptunnel configuration page where it says “Website name”. This will replace the default “mysite.i2p”.
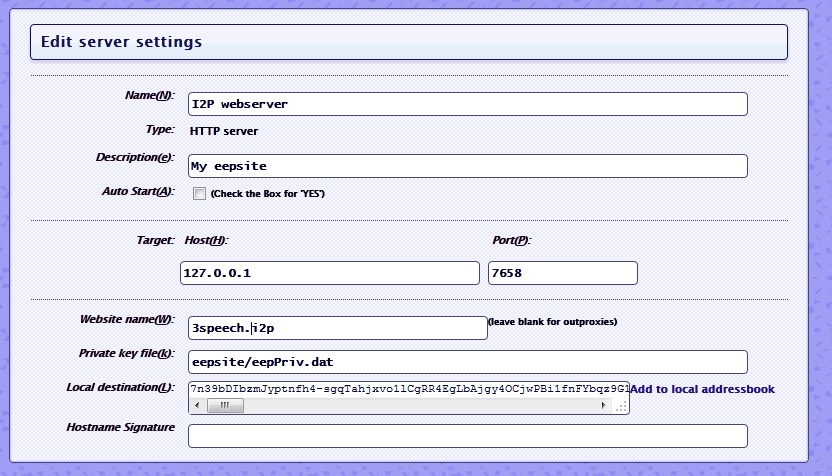
Highlight the entire “Local destination” key on the eepsite i2ptunnel configuration page and copy it for later pasting. Make sure you get the whole thing – it’s over 500 characters and it must end in “AAAA”. Enter the name and paste in the destination key into your master address book. Click “Add” to add the destination to your address book.
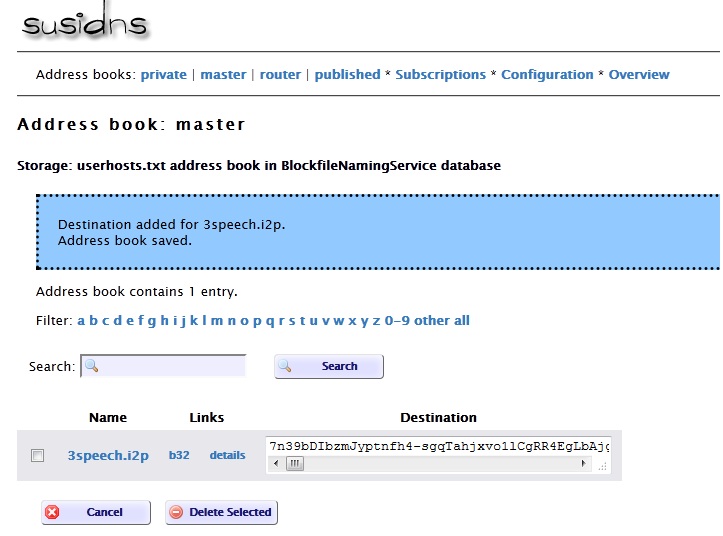
The final step is registering the eepsite in an address book hosted by i2p, which is part of the NetDB (explained in the about I2P post). Go to stats.i2p. Again, your key is the entire “Local destination” key on the eepsite i2ptunnel configuration page. After adding it, we can check to see if it reports the key was added. Since many routers periodically get address book updates from these sites, within several hours others will be able to find your website by simply typing 3speech.i2p into their browser.
We also used this video to learn how to host an eepsite by creating a new HTTP server tunnel and to map it to a virtual host rather than use the default Jetty. We did not actually do this because we do not have an external server to use.
Technologies Used
Posted by drakopoulos in Technical Details on May 2, 2012
Programming Language / Framework

The chosen language of 3speech implementation is Ruby, which is a dynamic, reflective, general-purpose, open source, object-oriented programming language. Ruby supports multiple programming paradigms, including functional, object oriented, imperative and reflective. 3speech was developed using the Ruby on Rails, open source full-stack web application framework which is a variant of the Model/View/Controller (MVC) architecture pattern to organize application programming. Ruby on Rails is a full-stack framework, meaning that it gave us the full ability to gather information from the web server, talking to or querying the database, and template rendering out of the box.
Web Server
I2P Webserver – A tunnel pointed to a Jetty webserver run on localhost:7658 for convenient and quick hosting on I2P.
The document root is:
Unix – %APPDATA%\I2P\eepsite\docroot
Windows – C:\Users\**username**\AppData\Roaming\I2P\eepsite\docroot
A future consideration is to use server virtualization, which is the partitioning of a physical server into smaller virtual servers to help maximize our server resources. In server virtualization the resources of the server itself are hidden, or masked, from users, and software is used to divide the physical server into multiple virtual environments.
Server virtualization also conserves space through consolidation as several machines can be consolidated into one server running multiple virtual environments. It also utilizes resources to the fullest so we can also save on operational costs (e.g. using a lower number of physical servers reduces hardware maintenance).
Database choice: NOSQL
NoSQL, which most now take to mean “Not Only SQL,” is a new non-relational approach to data
management that supports dynamic and flexible schemas, optimized storage for web scale, and
extreme performance as well as makes semi-structured and unstructured data easier to use and
access. Although RDBMS technology is still a good fit for critical transactional applications, new types of applications are motivating architects to look elsewhere when the relational approach falls short. Craigslist, Facebook, Twitter, Yahoo, and YouTube have already used NoSQL to support demanding web-scale applications. Although adoption of NoSQL in enterprises is around 4%, Forrester expects this to double in the next two years and that by 2015, 20% of enterprises will use NoSQL to support some or all of their applications. This is one of the major reasons for choosing to use NoSQL.
NoSQL offers several benefits in the areas of data management, access, storage, scale, and performance that make it a viable alternative to RDBMS. NoSQL delivers:
Flexible schema structures to support new types of applications.
Unlike an RDBMS, which requires the application developer to predefine data attributes, entities, and relationships, NoSQL offers a more flexible approach in which the application rather than the data store defines the schema and access paths. NoSQL supports a wide range of new data types, including textual types such as JSON as well as many other unstructured and semistructured data types. NoSQL’s inclusion of these flexible schemas and data types makes it easier to build new types of social media, cloud, and other scale-out applications.
High-performance key-value data reads and writes.
Applications that require extensive data reads and writes often experience excessive latency due to disk input/output (I/O) bottlenecks, especially when the app has high volumes of both. NoSQL approaches are efficient at reading very large amounts of data in a scale-out model, with each node in a cluster having its own I/O channels and controllers to deliver linear scale. For example, Twitter spreads accounts across thousands of nodes using a key-value store, and millions of users get low latency while concurrently accessing data. Conversely, NoSQL is not well suited to joining entities unless the store contains prejoined data.
Elastic scale to support dynamic workloads.
Because of the need to partition data across multiple databases, it’s challenging to scale out an RDBMS to handle growth. This makes it challenging to use an RDBMS when building an application that can easily scale from a thousand to a million users. NoSQL’s shared-nothing, scale-out architecture makes it easy to add nodes in a cluster or cloud to deliver linear scale.
Simplicity that makes it easy to get started.
NoSQL solutions have a fourth of the features of a typical RDBMS. This makes NoSQL easier to learn than a traditional DBMS as well as simpler to use when developing and deploying applications. From what we heard in interviews in the past year, many application developers like the simplicity and ease of using NoSQL in development. When using NoSQL, application developers have complete control over data storage and access and typically don’t need a database administrator (DBA) to support the NoSQL data store.
A lower-cost data management platform.
Many NoSQL solutions are open source, and others sell for much less than a full version of a commercial RDBMS. Compared with conventional DBMSes, NoSQL products often save enterprises more than 50% of the cost.
Freedom to innovate.
NoSQL is for application developers and programmers who want complete control and flexibility to store and access data in the manner they want without having to comply with the constraints and rigid structures an RDBMS imposes.

Neo4j is an open-source graph database, implemented in Java. The developers describe Neo4j as “embedded, disk-based, fully transactional Java persistence engine that stores data structured in graphs rather than in tables”.
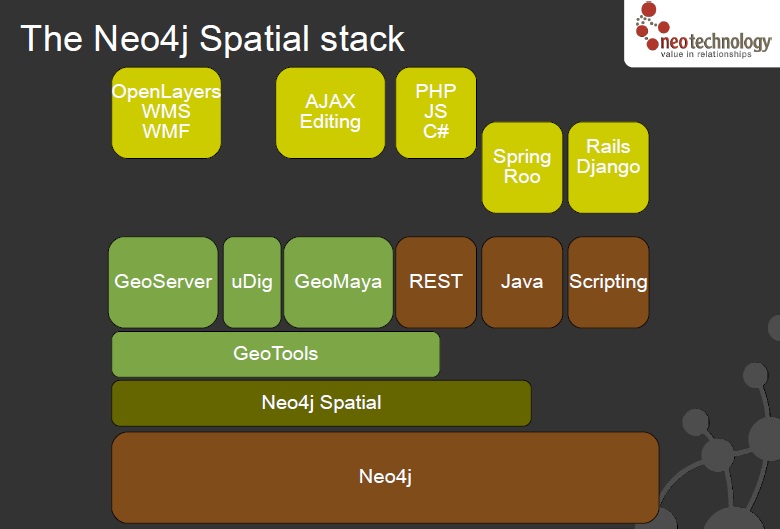
Key benefits*
A graph data model which enables high performance queries on the complex, connected data inherent in today’s applications. You can ask questions such as “Who are all my contacts in Europe?” and “Which of my contacts ordered from this catalog?” It can traverse complex graphs with improvements of 1000x or more compared to SQL and other NOSQL databases.
A graph data model which simplifies the development of applications using complex, connected data. Enterprises can quickly capture all kinds of data – structured, semi-structured, and unstructured – and easily store it in Neo4j. This results in shorter development times, lower maintenance costs and higher performance.
Mature support for transactions so that enterprise developers can execute “all or nothing” transactions. Although this is a must-have for relational databases, none of the other NOSQL databases can do this. Neo4j supports full ACID transactions including XA-compliant distributed two-phase commits.
Enterprise-grade durability that ensures that any transaction committed to the database will not be lost. I
Awesome Java support. While supporting all of the leading development platforms, (Ruby, Python, Groovy, Gremlin, etc) Neo4j began in Java and will always be easily accessible and available for Java, the most widely used development environment in the enterprise.
This was also incredibly help full in helping us learn about representing our social network in the database: Social Network in the Database: Using a Graph Database
*Taken from the neo4j website.
NoSQL
Posted by drakopoulos in Technical Details on May 1, 2012
NoSQL, which most now take to mean “Not Only SQL,” is a new non-relational approach to data management that supports dynamic and flexible schemas, optimized storage for web scale, and extreme performance as well as makes semi-structured and unstructured data easier to use and access. Although RDBMS technology is still a good fit for critical transactional applications, new types of applications are motivating architects to look elsewhere when the relational approach falls short. Craigslist, Facebook, Twitter, Yahoo, and YouTube have already used NoSQL to support demanding web-scale applications. Although adoption of NoSQL in enterprises is around 4%, Forrester expects this to double in the next two years and that by 2015, 20% of enterprises will use NoSQL to support some or all of their applications. This is one of the major reasons for choosing to use NoSQL.
NoSQL offers several benefits in the areas of data management, access, storage, scale, and performance that make it a viable alternative to RDBMS. NoSQL delivers:
Flexible schema structures to support new types of applications.
Unlike an RDBMS, which requires the application developer to predefine data attributes, entities, and relationships, NoSQL offers a more flexible approach in which the application rather than the data store defines the schema and access paths. NoSQL supports a wide range of new data types, including textual types such as JSON as well as many other unstructured and semistructured data types. NoSQL’s inclusion of these flexible schemas and data types makes it easier to build new types of social media, cloud, and other scale-out applications.
High-performance key-value data reads and writes.
Applications that require extensive data reads and writes often experience excessive latency due to disk input/output (I/O) bottlenecks, especially when the app has high volumes of both. NoSQL approaches are efficient at reading very large amounts of data in a scale-out model, with each node in a cluster having its own I/O channels and controllers to deliver linear scale. For example, Twitter spreads accounts across thousands of nodes using a key-value store, and millions of users get low latency while concurrently accessing data. Conversely, NoSQL is not well suited to joining entities unless the store contains prejoined data.
Elastic scale to support dynamic workloads.
Because of the need to partition data across multiple databases, it’s challenging to scale out an RDBMS to handle growth. This makes it challenging to use an RDBMS when building an application that can easily scale from a thousand to a million users. NoSQL’s shared-nothing, scale-out architecture makes it easy to add nodes in a cluster or cloud to deliver linear scale.
High-performance key-value data reads and writes.
Applications that require extensive data reads and writes often experience excessive latency due to disk input/output (I/O) bottlenecks, especially when the app has high volumes of both. NoSQL approaches are efficient at reading very large amounts of data in a scale-out model, with each node in a cluster having its own I/O channels and controllers to deliver linear scale. For example, Twitter spreads accounts across thousands of nodes using a key-value store, and millions of users get low latency while concurrently accessing data. Conversely, NoSQL is not well suited to joining entities unless the store contains prejoined data.
Elastic scale to support dynamic workloads.
Because of the need to partition data across multiple databases, it’s challenging to scale out an RDBMS to handle growth. This makes it challenging to use an RDBMS when building an application that can easily scale from a thousand to a million users. NoSQL’s shared-nothing, scale-out architecture makes it easy to add nodes in a cluster or cloud to deliver linear scale.
Freedom to innovate.
NoSQL is for application developers and programmers who want complete control and flexibility to store and access data in the manner they want without having to comply with the constraints and rigid structures an RDBMS imposes.
Five challenges of NoSQL
The promise of the NoSQL database has generated a lot of enthusiasm, but there are many obstacles to overcome before they can appeal to mainstream enterprises. Here are a few of the top challenges.
Maturity
RDBMS systems have been around for a long time. NoSQL advocates will argue that their advancing age is a sign of their obsolescence, but for most CIOs, the maturity of the RDBMS is reassuring. For the most part, RDBMS systems are stable and richly functional. In comparison, most NoSQL alternatives are in pre-production versions with many key features yet to be implemented. Living on the technological leading edge is an exciting prospect for many developers, but enterprises should approach it with extreme caution.
Support
Enterprises want the reassurance that if a key system fails, they will be able to get timely and competent support. All RDBMS vendors go to great lengths to provide a high level of enterprise support. In contrast, most NoSQL systems are open source projects, and although there are usually one or more firms offering support for each NoSQL database, these companies often are small start-ups without the global reach, support resources, or credibility of an Oracle, Microsoft, or IBM.
Analytics and business intelligence
NoSQL databases have evolved to meet the scaling demands of modern Web 2.0 applications. Consequently, most of their feature set is oriented toward the demands of these applications. However, data in an application has value to the business that goes beyond the insert-read-update-delete cycle of a typical Web application. Businesses mine information in corporate databases to improve their efficiency and competitiveness, and business intelligence (BI) is a key IT issue for all medium to large companies. NoSQL databases offer few facilities for ad-hoc query and analysis. Even a simple query requires significant programming expertise, and commonly used BI tools do not provide connectivity to NoSQL. Some relief is provided by the emergence of solutions such as HIVE or PIG, which can provide easier access to data held in Hadoop clusters and perhaps eventually, other NoSQL databases.
Administration
The design goals for NoSQL may be to provide a zero-admin solution, but the current reality falls well short of that goal. NoSQL today requires a lot of skill to install and a lot of effort to maintain.
Expertise
There are literally millions of developers throughout the world, and in every business segment, who are familiar with RDBMS concepts and programming. In contrast, almost every NoSQL developer is in a learning mode. This situation will address naturally over time, but for now, it’s far easier to find experienced RDBMS programmers or administrators than a NoSQL expert.
References
[1] Stonebraker, M. “SQL databases v. NoSQL databases.” Commun. ACM 53(4) (April 2010), pp. 10 – 11.
[2] Leavitt, N., “Will NoSQL Databases Live Up to Their Promise?,” Computer , 43(2), Feb. 2010 pp.12 – 14.
[3] Yuhanna, N., “NoSQL Offers New Options for Application Developers”, Forrester Research, September 2011, ID: 60237
[4] Hopkins, B., “Big Opportunities in Big Data”, Forrester Research, May 2011, ID: 59321
Connecting to I2P
Posted by drakopoulos in Technical Details on April 19, 2012
The following tutorials were used to learn how to connect to the I2P network and how to implement any necessary configurations:
Installing on Windows:
http://www.youtube.com/watch?v=WyN_QK-_3GA
Further information can be found here.
Installing on Linux:
Installing on Apple OSX:
Network Selection
Posted by drakopoulos in Technical Details on April 19, 2012
Having examined the existing anonymous networks and discussing the options in a group meeting, we narrowed down our choices to either the TOR network or the I2P network. We then proceeded to examine the various strengths and weaknesses of the two networks, before finally settling upon I2P. Below are the technical factors that lead us to our choice:
- I2P is completely decentralized, unlike Tor where a ‘directory’ of the network is maintained. Rather than building an essentially trusted, centralised system with directory servers, I2P has a self-organizing network database with each peer taking on the responsibility of profiling other routers to determine how best to exploit available resources.
- While Tor was designed with the intention to enable anonymous Internet browsing, I2P’s focus is to provide an anonymous network, isolated inside the Internet, off ering various protocols and applications within. Furthermore, I2P is designed and optimised for “hidden services” (i.e. websites and other services hosted within I2P), and they are much faster than the corresponding ones on the Tor network, as the I2P network is fully distributed and self-organizing.
- Content hosted on networks such as Freenet are mostly static, whereas websites hosted within I2P can be fully dynamic
- I2P is fundamentally a packet switched network whereas Tor is fundamentally a circuit switched network. This allows I2P to transparently route around congestion and other network failures, operate redundant pathways and load balance the data across available resources.
- Although Tor is more popular and has significantly more funding than the I2P network, in recent times the network has become incredibly saturated and is more vulnerable. In contrast, the smaller size of I2P has allowed it thus far to float beneath the radar of government censors and malicious users.
- The unidirectional tunneling system used by I2P doubles the amount of nodes that a peer needs to compromise to get the same information that could be obtained from Tor’s bidirectional tunneling system. In addition to this, tunnels in I2P are short lived, decreasing the number of samples that an attacker can use to mount an active attack with, unlike circuits in Tor, which are typically long lived.
Architecture of I2P (the following section was taken from the technical documentation of I2P, located here):
How it works:
I2P uses bundled encryption over a multi-proxy like Tor. The packets are bounced all over the globe using I2P. However, the packets are encrypted with EIGamal and AES encryption. Using bundled encryption like this allows a packet to only decrypt the next hop as it passes through various nodes on its path. Once inside the network, IP addresses are not even used. Your node is assigned an address of garbled text to use an identifier.
I2P uses virtual, unidirectional tunnels that pass through a series of routers, and are typically 2 to 3 hops. Each round trip message and reply will require 4 tunnels. One for each the sender and receivers inbound/outbound traffic. Tunnels are created using what is known as ‘garlic routing’. A tunnel build message is sent via garlic routing to an I2P router requesting that it participate in a tunnel.
I2P makes a strict separation between the software participating in the network (a ‘router’) and the anonymous endpoints (‘destinations’) associated with individual applications. The fact that somebody is running I2P isn’t usually a secret. What is hidden is the information on what the user is doing as well as what router a particular destination is connected to. End users will typically have several local destinations on their router.
Tunnels:
A tunnel is a directional path through an explicitly selected list of routers. Layered encryption is used, so each of the routers can only decrypt a single layer. The decrypted information contains the IP of the next router, along with the encrypted information to be forwarded. Each tunnel has a starting point (the 1st router (gateway)) and an endpoint. Messages can only be sent one way. To send messages back, another tunnel is required.
Two types of tunnels exist:
- “Outbound” tunnels send messages away from the creator.
- “Inbound” tunnels bring messages to the tunnel creator.
While the tunnels themselves have layered encryption to prevent unauthorized disclosure to peers inside the network (as the transport layer itself does to prevent unauthorized disclosure to peers in the network), it is necessary to add an additional end to end layer of encryption to hide messages from the outbound tunnel endpoint endpoint and the inbound tunnel gateway. This achieved by a process known as ‘garlic routing’.
Garlic Routing:
I2P uses an extension of the well-known onion routing approach, in which a message is routed from its originator to the final endpoint through several intermediate nodes using layered encryption. The originator adds to the message to be sent an encryption layer for every node in the path, each intermediate node peels off one of these layers, exposing routing instructions along with still-encrypted payload data, and finally the last node removes the final layer of encryption, exposing the original message to the endpoint. This process is called garlic routing, and allows to the originator include several messages in a single onion. I2P currently uses this approach to include the return destination for a given message as well as status messages.
The ‘instructions’ attached to each clove inside the encryption layer includes the ability to request that clove be forwarded locally, to a remote router, or to a remote tunnel on a remote router. There are fields in those instructions allowing a peer to request that a delivery be delayed until a certain time or condition has been met, though they won’t be honoured until the non-trivial delays are deployed.
Network Database (NetDB):
The NetDB uses a pair of algorithms which are used to share network metadata. The two types of metadata carried are “routerinfo” and “leasesets” – the routerinfo gives routers the data necessary for contacting a particular router (their public keys, transport address etc.) while the leaseset give routers the information necessary for contacting a particular destination. The full info contained in the leaseset is:
- Inbound gateway for a tunnel that allows reaching a specific destination.
- Time when a tunnel expires.
- Pair of public keys to be able to encrypt the messages (to send through the tunnel).
Routers themselves send their router information to the netDB directly, while leasesets are sent through outbound tunnels (leasesets need to be sent anonymously, to avoid correlating a router with his leaseset).
The following sources were used for this post: