Structural framework
About this page
This document is the framework on which we will build the guidance documentation that will constitute one of the final deliverables of the CREAM project. Our intention is to assemble in this document the information to enable the recognition, characterisation, and exploitation of metadata used actively. While we have recognised more areas of commonality between the arts and sciences than we had anticipated and have gained a great deal from the collaborative activities between partners, we have also observed differences between the domains represented by the project partners. To cover the scope of active metadata use, and the likely variations between different target audiences, we propose to supplement the guidance with shorter, domain-specific, exemplars to facilitate navigating the guidance. These exemplars will also attest to the wider benefits of active metadata, as outlined within the next section.
About the active use of metadata
When we refer to ‘active metadata’ or, more accurately, the active use of metadata, we are not expounding a new and special class of metadata: we are instead exploring how to use metadata to inform future work within a research process. We want to ensure that our metadata means more; we are interested in what we can achieve with metadata.
Accordingly, we are impartial about the nature of metadata. At one time, metadata was described rather glibly as “data about data” but that representation, and other, more considered, descriptions, suffered from a dependence on perspective: one person’s metadata is another person’s data.
Nevertheless, it is worth pausing to consider two extracts from Michener et al [Ecological Applications, 7(1), 330-342, 1997]:
“Ideally, metadata comprise all information that is necessary and sufficient to enable long-term secondary use (reuse) of the data set by the original investigator(s), as well as use by other scientists who were not directly involved in the original research efforts.”
“The most important reason to invest time and energy in developing metadata is that human memory is short. If data are to undergo any secondary usage, then adequate metadata will be required even if that secondary usage consists of reuse by the data originator.”
Nearly 20 years ago, Michener et al foresaw the significance of using metadata to inform future work, and we are optimistic that that they would subscribe to our working definition:
“Active metadata is the assemblage of metadata and annotations that is used actively within the project or process that generates it and is capable of being reused within that project or by another process.”
This explanation would be incomplete without a summary of the wider benefits of the active use of metadata. The recording of active use facilitates transparency and greater understanding, notably for cross-domain collaborations, which it can make easier and more productive. Active use also facilitates reproducibility or, if a procedure was unsuccessful, it simplifies subsequent failure analysis. The GeosMeta illustrated scenario at the end of this document provides an example of using metadata actively to flag errors.
The following example is a compact illustration of the active use of metadata, chosen intentionally not to be associated with any of the domains represented by the partners in the CREAM project (except possibly chemistry!):
Imagine that you are cooking a meat pie. The recipe tells you to bake the pie at a certain temperature until the crust is golden brown, so that’s what you do. The crust is just right but the meat is rather tough, so you think that next time you will bake your pie at a lower temperature but for longer. Pie number two is much better, so you decide you ought to pass on your findings to other cooks. You know your two metadata elements, time and temperature, and you know both sets of values, so you have recognised your active use and have done the first stage of capture.
The sections of this framework indicate the anticipated structure of the guidance:
- A review of who might benefit from a fuller understanding of active
metadata use: the target audiences; - A consideration of the nature of active use and how it relates it to
other topics, such as provenance; - A description of the support required for characterising and
exploiting active use;
The framework concludes with three illustrated scenarios.
Target audiences
A list of ‘personas’, each with a brief reason for their interest:
We can roughly categorise the audiences according to their roles:
- Doers: researchers; artists; project leaders; supervisors; tool developers
- Facilitators: research managers and their advisors; data managers; librarians
- Enablers: funders; publishers
- Influencers: funders; reviewers; evaluators
Although the Doers are the people who actually use the metadata actively, we consider it important that Facilitators, Enablers, and Influencers understand the concept well enough to ensure their full support for the Doers.
Outline use cases, amplifying the reasons for interest:
Example: A project leader wants to understand how a particular factor is influencing the process that is the subject of his team’s research. He takes the metadata captured during a laboratory experiment and asks another member of the team to adapt the simulation of the process to take account of that metadata. Using the results of the simulation, he suggests a further laboratory experiment with a different metadata value.
In the final documentation, we will consider use cases that represent the interests of the other roles listed above.
Common themes
This sub-section will explore the common aspects of why different ‘personas’ are interested in the active use of metadata. A basic example would be to improve the efficiency of a process.
What active use is and is not
The crucial distinction is that active use is not about the capture of the metadata; it is about the use of that metadata. It is not so much what you have as what you can do with it.
In a sense, active metadata offers the means to put plans into practice optimally, allowing researchers to understand how the prospective provenance, embodied in the plan, evolved into the retrospective provenance: what actually transpired. As such, active metadata has been described as “the filling in the provenance sandwich.
Although active metadata is related to provenance, and can be a component of workflow, the principal differences lie in the ways it is used.
Active metadata will most likely be intimately bound to the processes that create and use it. Decisions and the motivations for why they were taken are an important aspect of such metadata, and of the process that generates it.
Identifying and evaluating decision points may aid understanding a process, identifying errors and alternative uses. Provenance information may inform understanding of why specific metadata has been activated, and its influence on a process may in turn inform the provenance of process outputs.
Accordingly, active metadata includes information about decisions made in the conduct of a process, the data upon which they are based, and provenance of that data. In principle, capturing decision points and the actively used metadata that influenced each decision should be reasonably straightforward, although representing them will require careful consideration.
How active use relates to other topics
Data capture
The aspect of data capture that is fundamental to active use is the proper recording of the context. It is knowledge of the context that enables us to understand the data and to make predictions about the effects of changes to the context. When we use or reuse the “assemblage of metadata and annotations” that comprise the context, we are using the metadata actively.
Provenance
Provenance information (in the sense of process provenance, e.g. [W3C PROV]) records the activities that form a process, and the entities (data and other artifacts) that are consumed and generated by those activities. Thus, provenance (sometimes called “retrospective provenance”) forms a post-hoc description of a completed process, and as such can provide key insights into the conduct of that process.
Planning
On the other hand, a process plan, or workflow template, (sometimes called “prospective provenance”) is used to describe steps in a potential process [P-PLAN, Wf4Ever].
Instantiation of a process plan as an actual process involves a number of decisions, including what inputs to use and, where allowed by the plan, which steps to perform and what processors or other facilities to use to perform those steps.
Workflow
The challenge to use metadata actively opens a range of new content and relationships, and requires flexible querying. Workflow is a class within this range, focusing on data flow as the relationship between actions. and is also one aspect or perspective of procedure that is closely linked to provenance: How was X made? Can I do it again?
Moreover, workflow management systems are current examples of active metadata use: for example, a specific workflow can be modified and reused.
RDM in general, but especially RDM planning
Most research funders now require data management plans (DMPs) at application time. This provides an opportunity to get researchers thinking early about active metadata. If researchers do not see DMPs as beneficial, because they do not appreciate the value of thinking about RDM at the start of the planning process, the resulting DMPs can be superficial.
Promoting the active use of metadata can help to inform project planning and to relate both with RDM planning, initially perhaps by adding further questions to the researcher to the
DMP Checklist, such as:
- “How do you plan to use metadata in your research process?”
- “Where in your project plan are the decision points that will affect how and what subsequent steps are performed?”
- “What is the information generated by the preceding steps that will inform those decisions?
The planning process might also include require researchers to consider the use of tools for capturing and structuring process context, as included in the toolset support that we envisage.
We will therefore consider including among the exemplars that will supplement the guidance documentation an example section from a data management plan, specifically addressing the capture of process context and the active use of that metadata.
Nature of the guidance in the final deliverable
The guidance documentation will include, in addition to the explanatory material in other sections, introductions to the other deliverables that will constitute the package of information to enable researchers to use metadata actively to make their research more effective, agile, and timely:
Toolset support for capturing and structuring process context, visualising active use, and accommodating different perspectives on the data acquired during the processes recorded
The Reliable Shared Vocabulary community tool (previously known as the Glossary)
We are also considering Tutorials to complement the exemplars that will supplement the guidance documentation.
Illustrated scenarios
GeosMeta
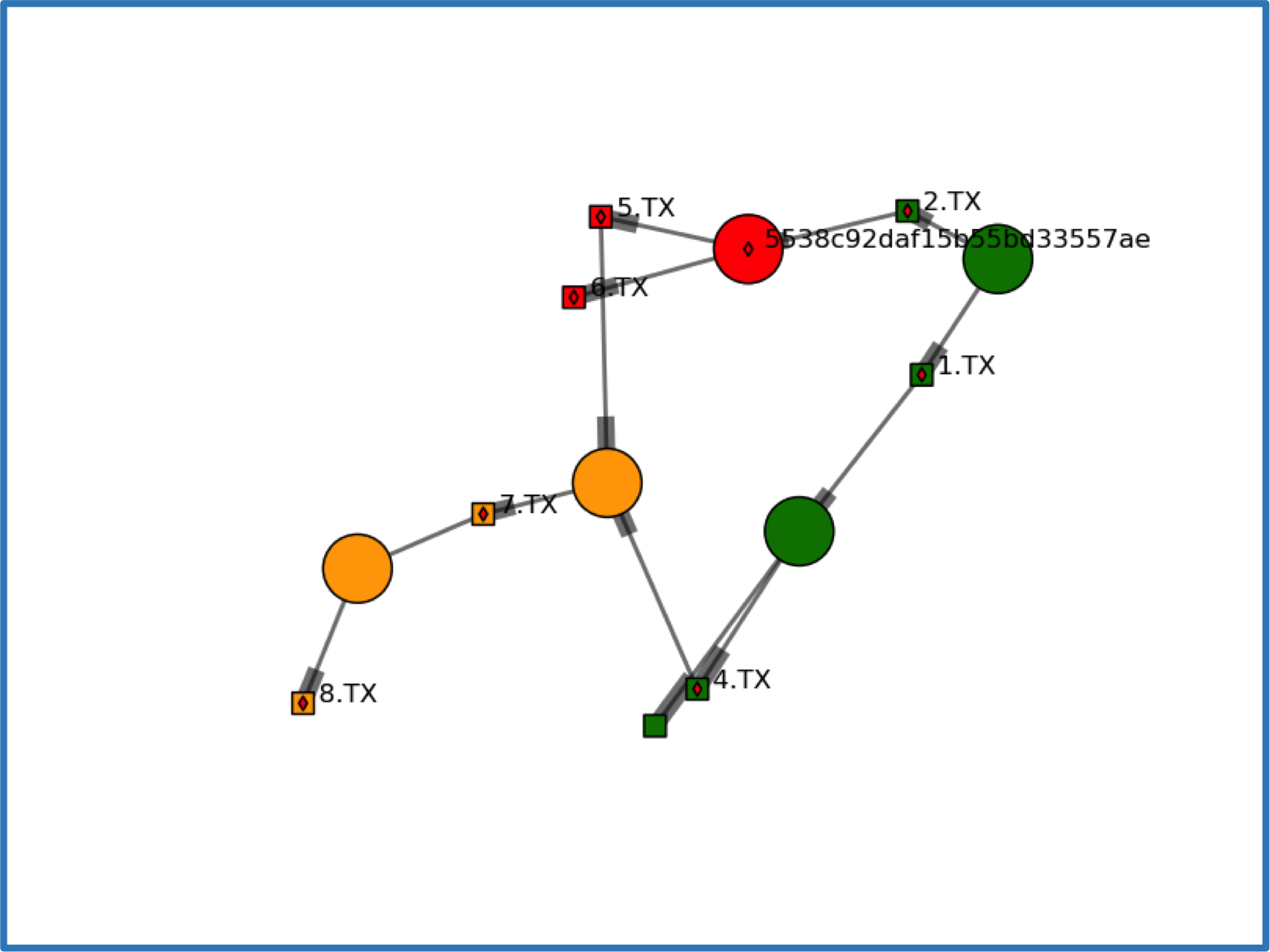
The diagram is an example of the use of GeosMeta to permit researchers to capture what they have done when running software, by holding metadata such as parameter values, input and output filenames, information on the executing computer, software versions, etc. The circles represent a document in the database. Each document holds metadata gathered during the execution of a script that takes input files and generates output files. The files are represented by the squares. The metadata are gathered by instrumenting the script with additional lines of code.
GeosMeta infers the researcher’s workflow from the separate steps they have executed, by use of the filenames. The flow in the diagram is from top right to bottom left, with the first document recording a script that made files 1.TX and 2.TX. The latter, 2.TX is then used in another script that generates 5.TX and 6.TX, and so on. In this case 5 scripts were run to make files here named from 1 to 8.TX.
To the routine metadata/provenance fields, GeosMeta adds a status history. The colours represent the status: green = current, red = in error, orange = downstream of an error. The researcher can redefine the status of a document via a call to a client function. In the diagram, the two green circles are still current and correct. However an error was discovered after making 5.TX and 6.TX, so that document’s status is reset. The 5538…. string is the unique identifier of the relevant document. The downstream documents and files also have a revised status inferred by the system.
The GeosMeta system provides client functions to write new documents, update their contents, amend status, search for a document, and retrieve a document. The client software invokes a RESTful API to communicate with MongoDB, via a frontend that uses EVE (http://python-eve.org/).
Active use of the metadata includes flagging that a file should not be reused because it is in error; discovering the processing chain that led to the existence of a particular file; seeing where a script or a data file has been used; finding where a particular parameter value has been used; capturing the status when an error is discovered; and inferring consequences for the validity of downstream data.
Procedural Blending

The diagram shows a blend diagram using concepts from Procedural Blending. The upper part illustrates the creation of the audio-visual piece “Smoke”; the lower part relates to a second audio-visual piece, “Fog”, for which the work began after the completion of “Smoke”. The boxes depict Blend Nodes, with those highlighted in the Smoke part having influenced the later work; while those highlighted in the Fog part were influenced by the earlier work. The dotted blue lines show where the diagram creator used Smoke metadata actively when making blending decisions while planning the Fog video.
Chemistry
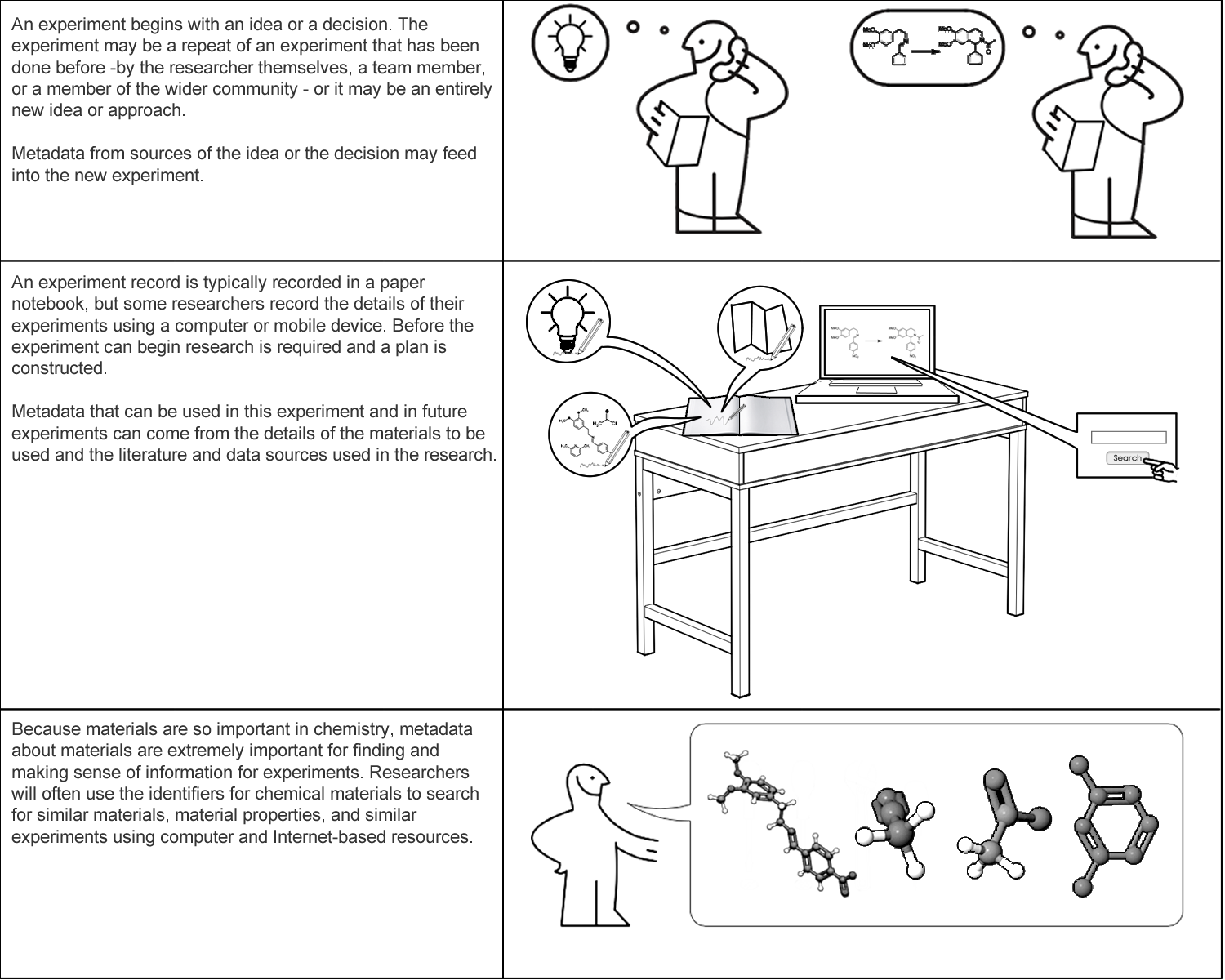
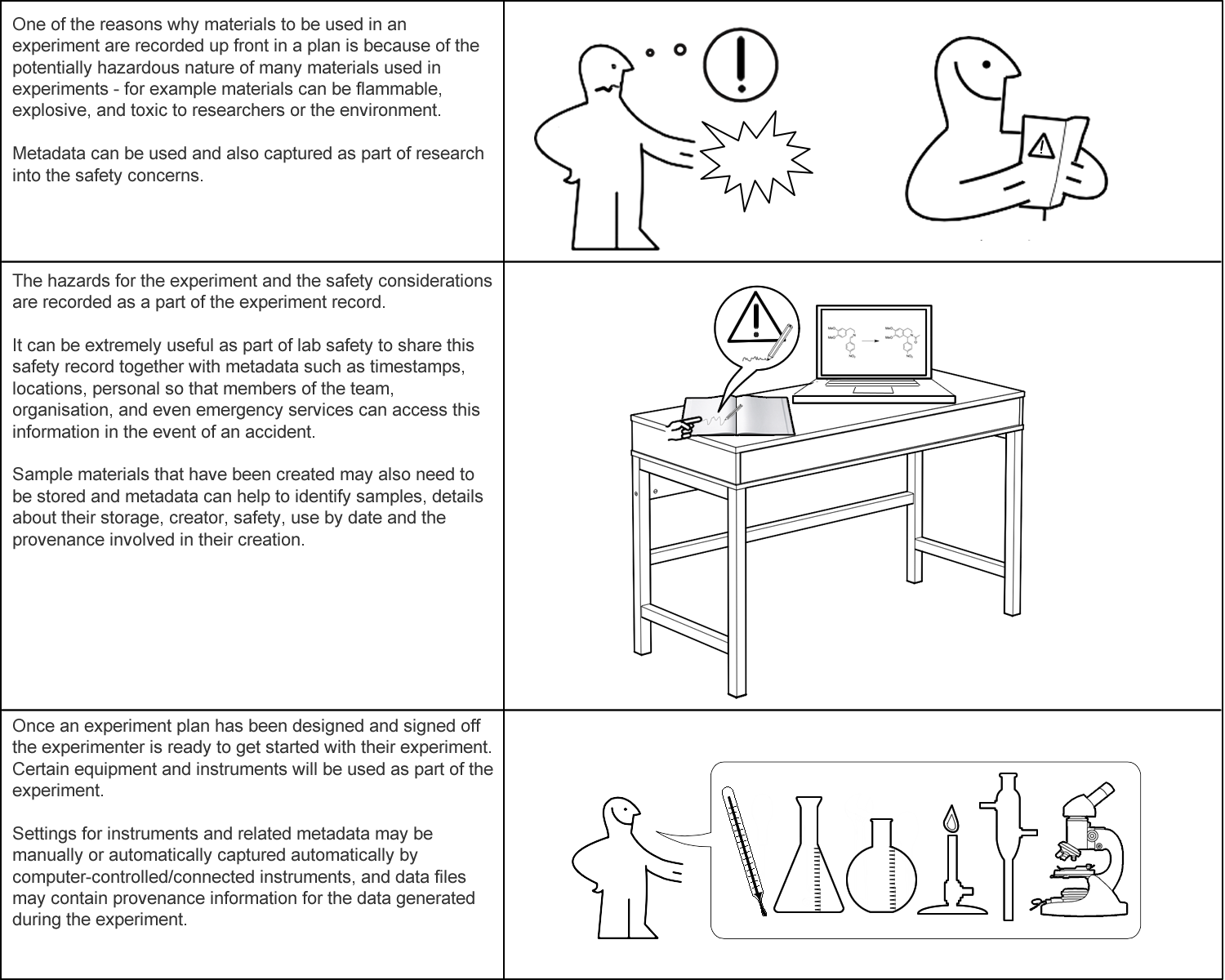
These diagrams are the first six of a longer set of annotated images intended to depict the activities, in and out of the laboratory, relating to a chemistry experiment. As well as describing the activities, the annotations point out the potential active use in such a scenario.
Leave a Reply