dotAC: A Linked Data Explorer for UKHE
Screenshots or diagram of prototype:
dotAC Explorer
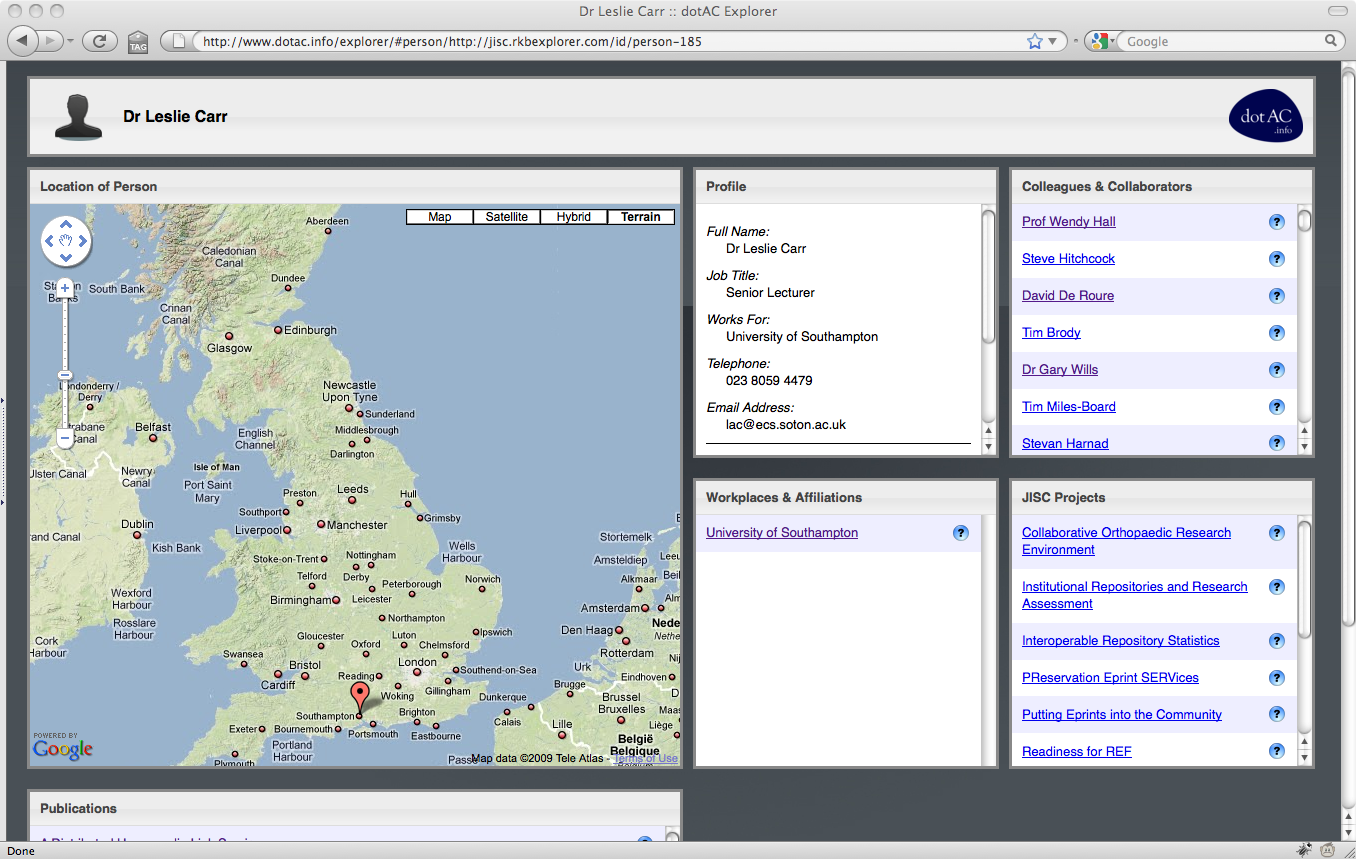
1. Examining Les Carr [link]
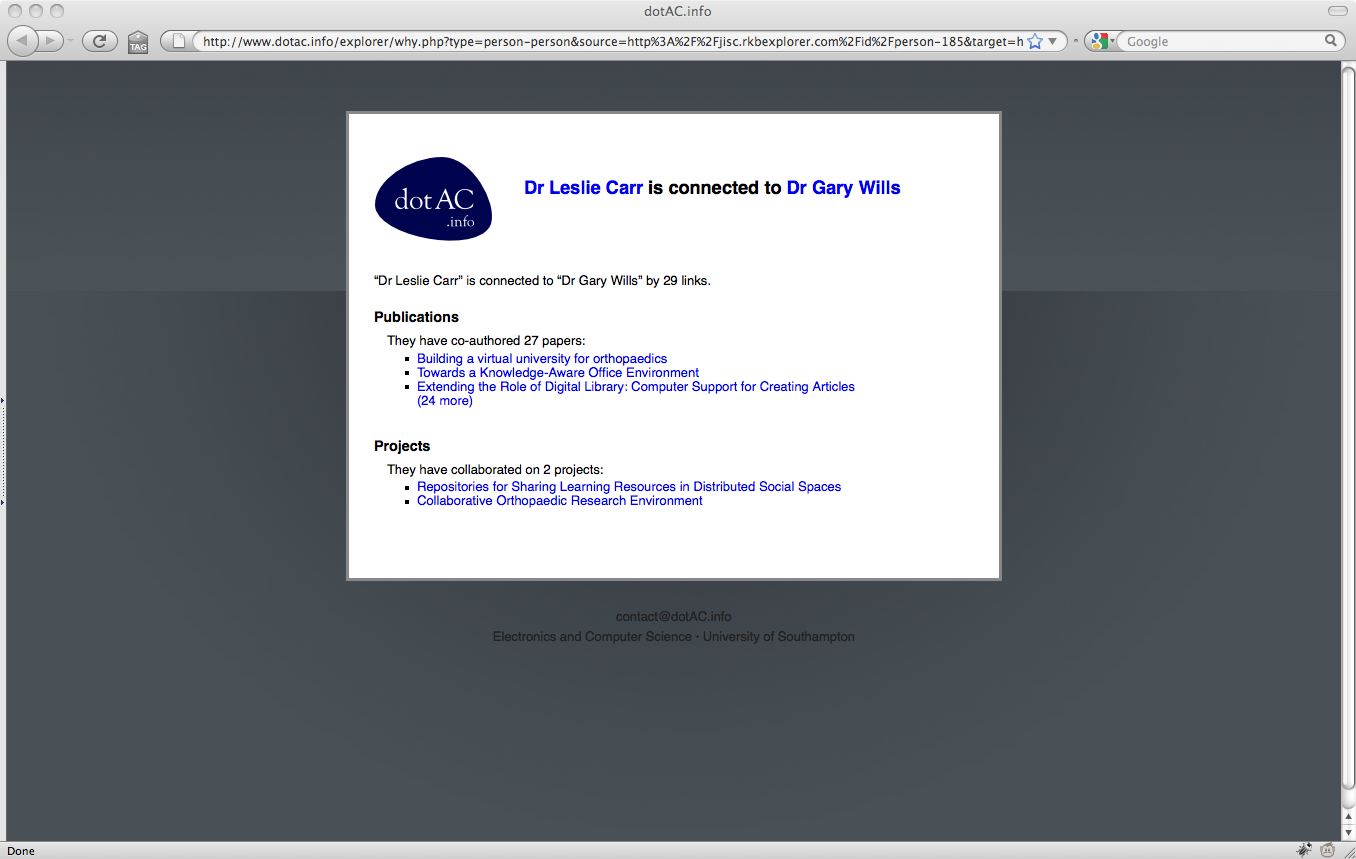
2. Why is Les Carr related to Gary Wills? [link]
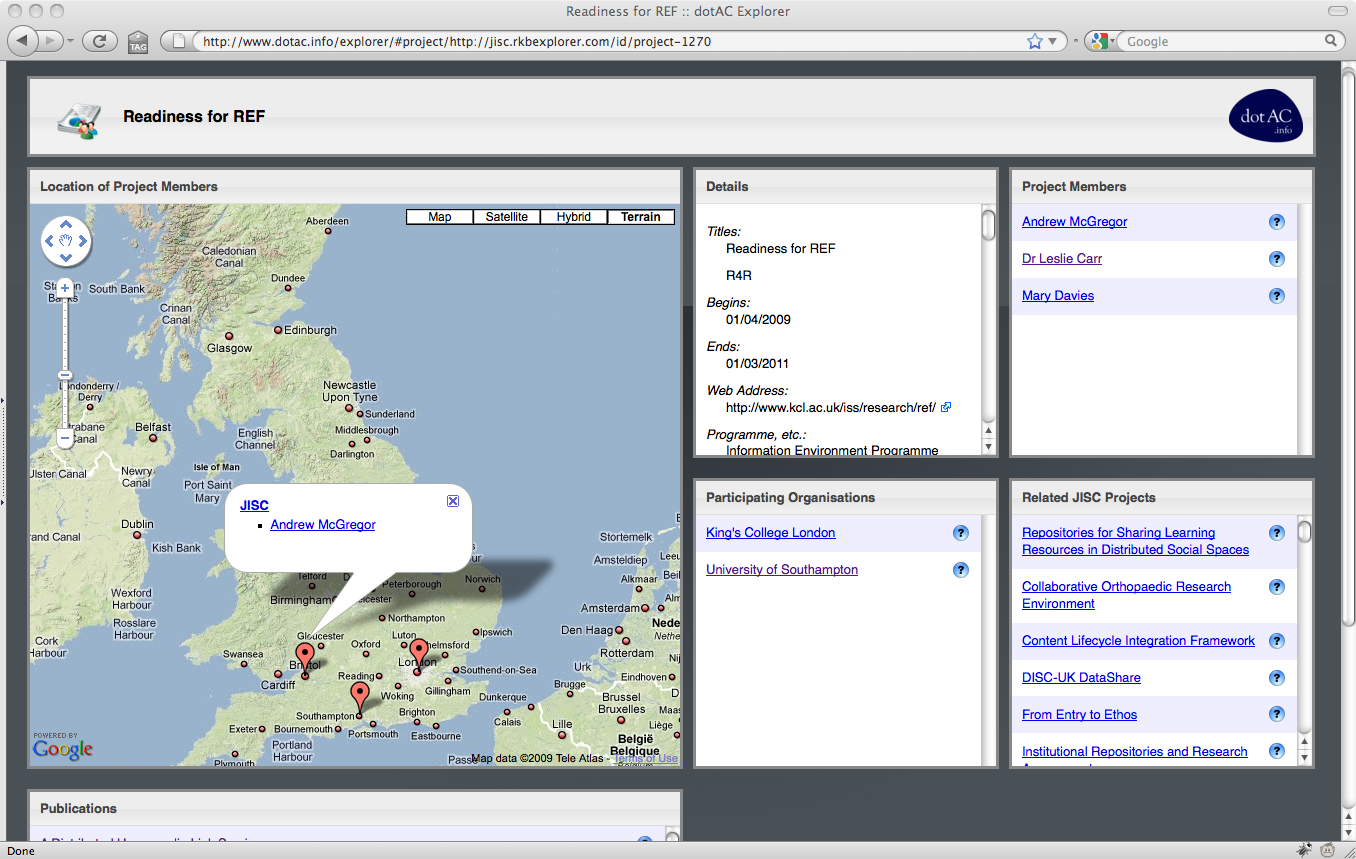
3. Examining the Readiness 4 REF project [link]
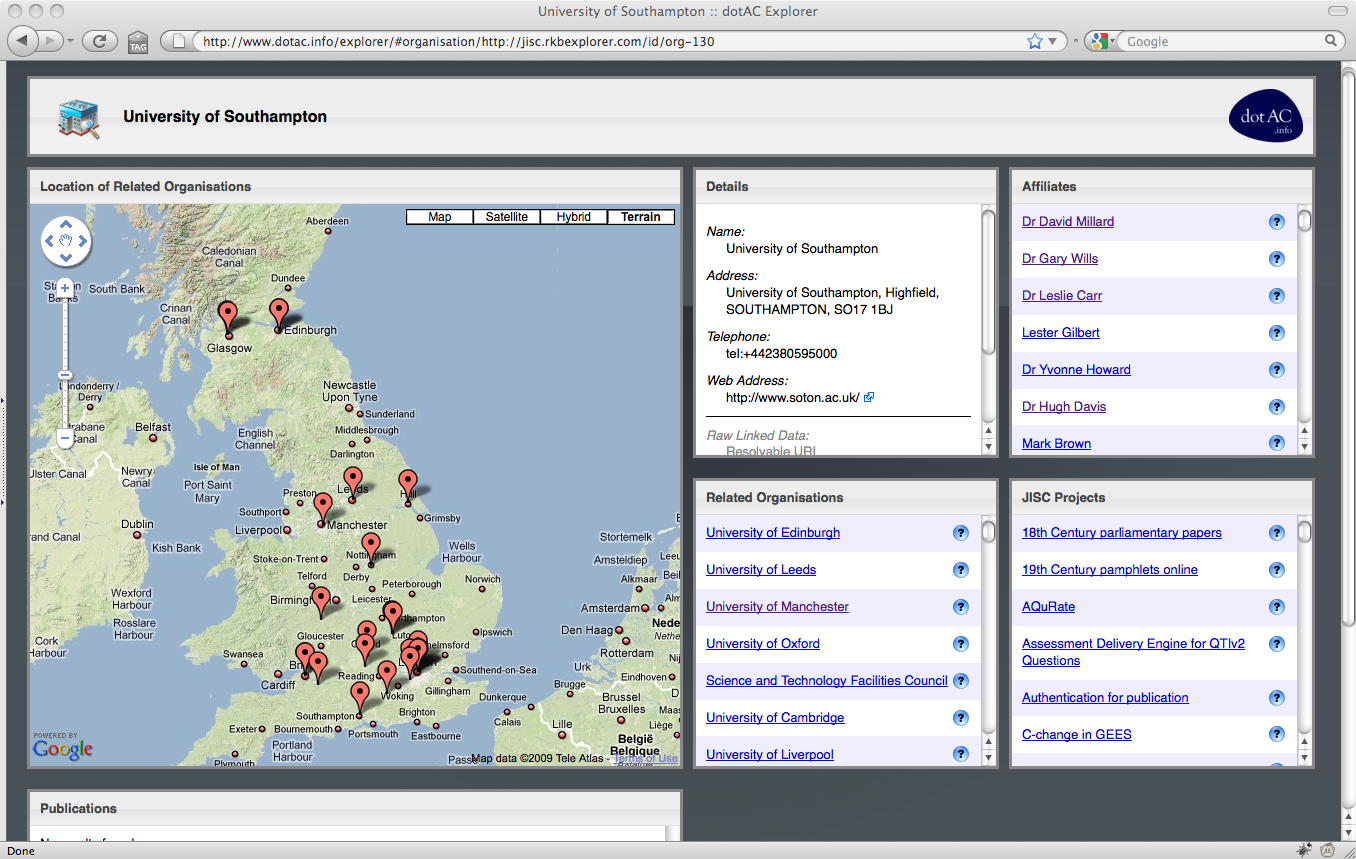
4. Examining the University of Southampton [link]
dotAC Editor
1. Loading initial bundles for “Les Carr”
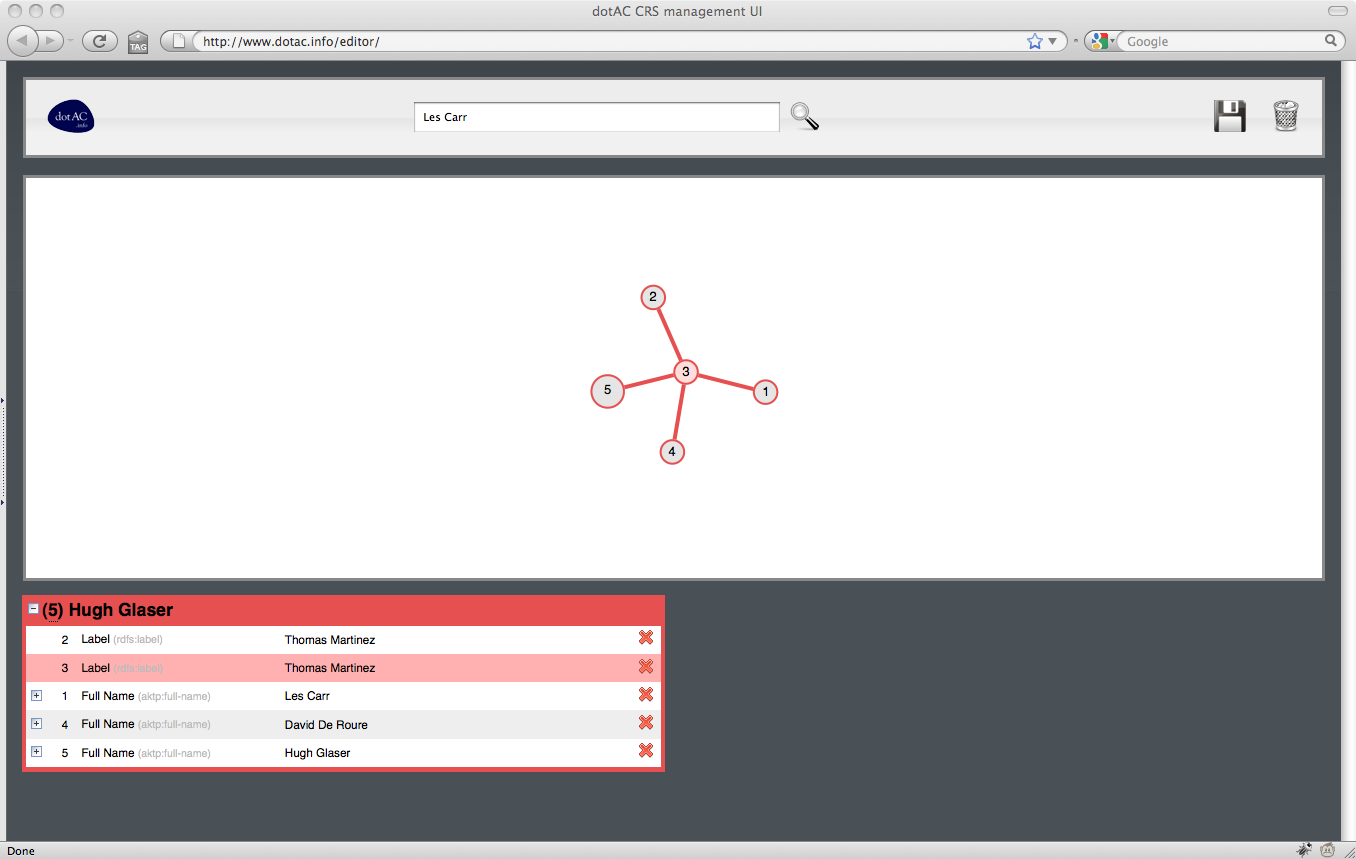
2. Examining Les Carr

3. Disconnecting Les Carr from the bundle
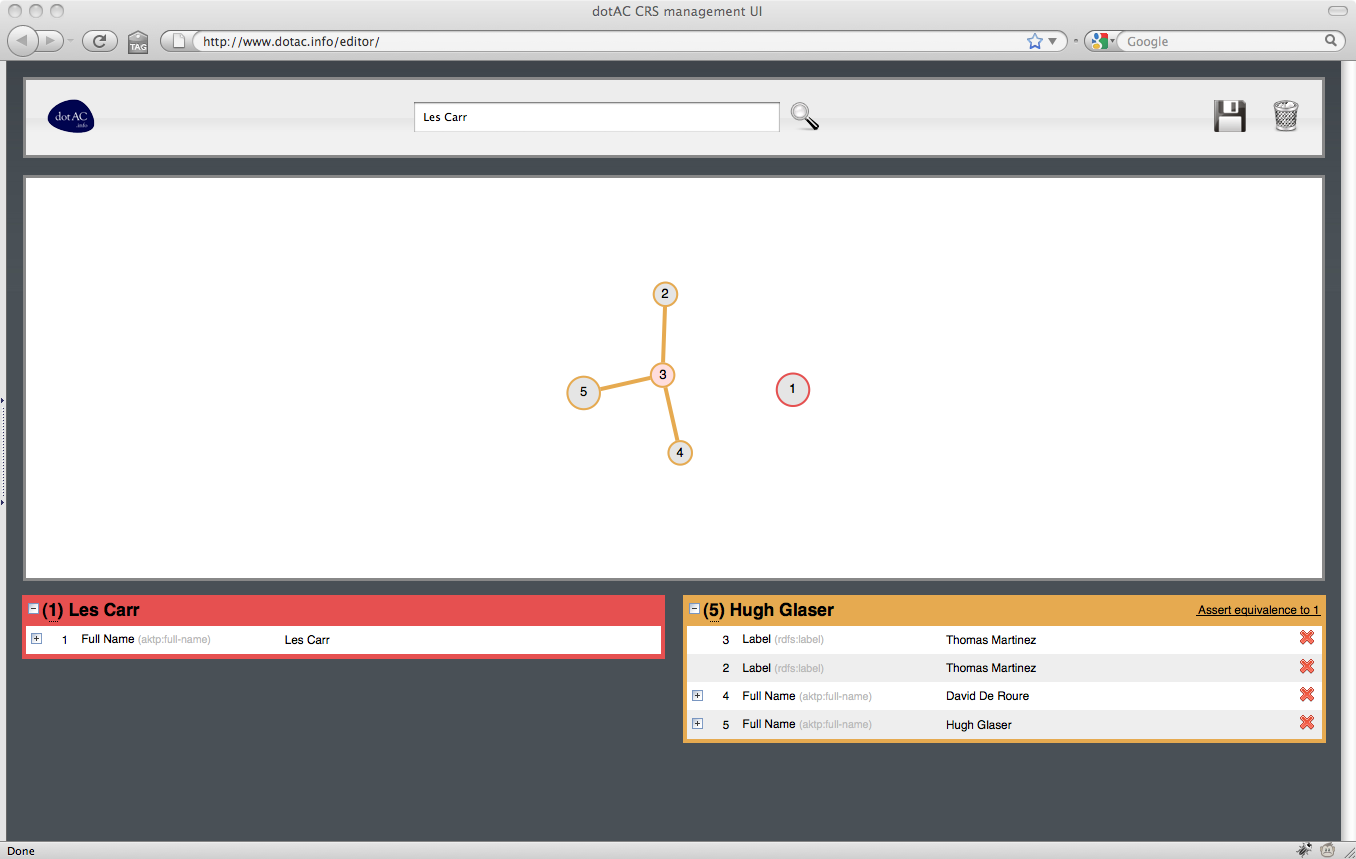
4. Isolating Thomas Martinez
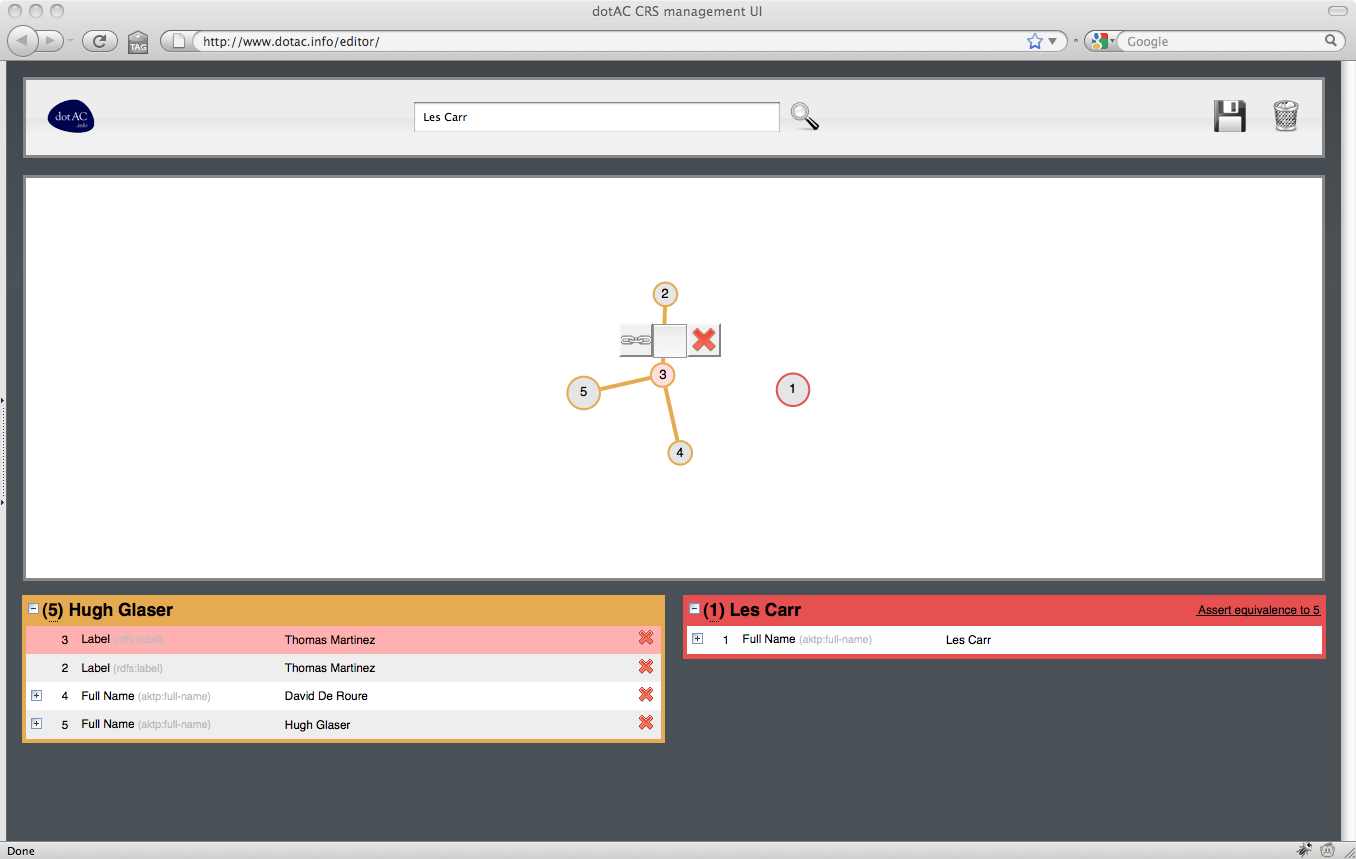

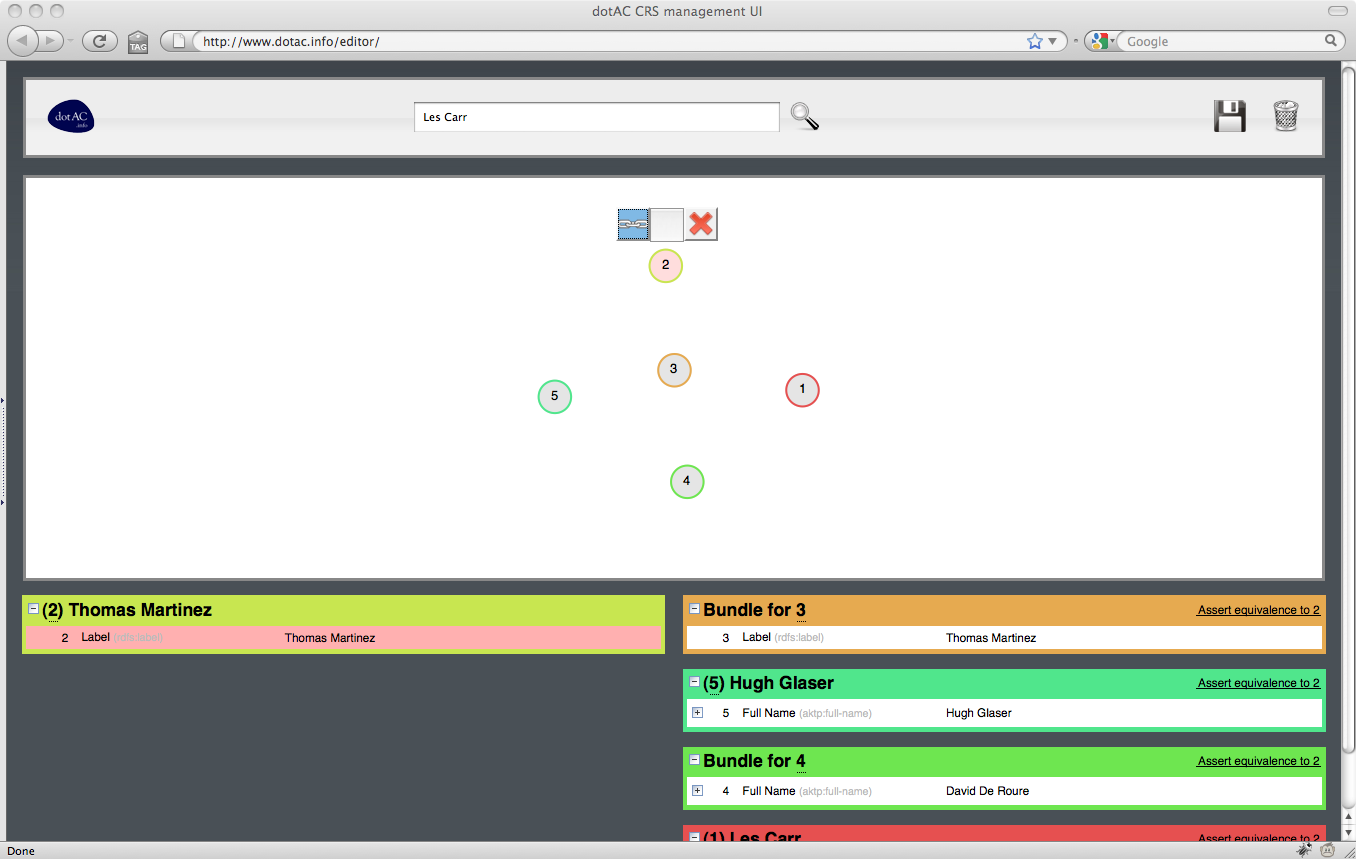
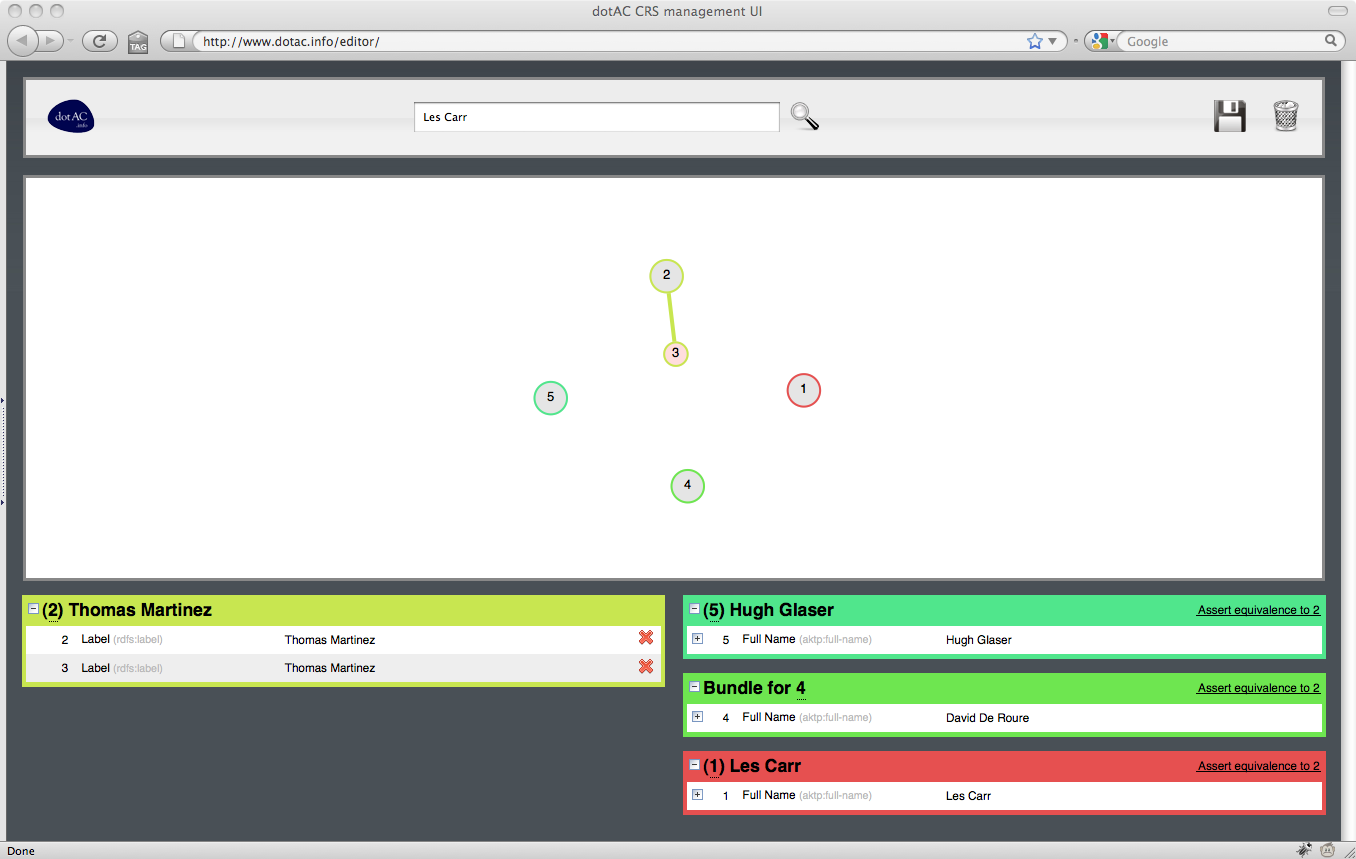
5. Joining Thomas Martinez bundles
Description of Prototype:
The dotAC prototype consists of three main components: the Explorer, the Coreference Editor, and the knowledge bases.
dotAC Explorer
The explorer is a faceted browser that allows the user to examine researchers, organisations, projects and publications within the JISC-funded UKHE community.
The interface consists of a number of panes: a geographical view, which indicates the location of the currently selected resource (or resources related to the currently selected resource), a detail view which allows the user to drill down and examine a resource in more depth, and a number of related resource views which show entities (people, projects, organisations, publications) that are related to the currently selected resource.
When a resource in any of these panes is selected, the page header changes to indicate that the focus of the explorer has changed, and the detail pane changes to provide extra information about the selected resource. The related resource panes will also change accordingly.
The explorer interface allows the user to investigate why a particular resource is related to the currently selected resource, by clicking the ? icon next to the related resource’s name. These relations typically take the form of co-authorship of papers, or co-investigation of projects.
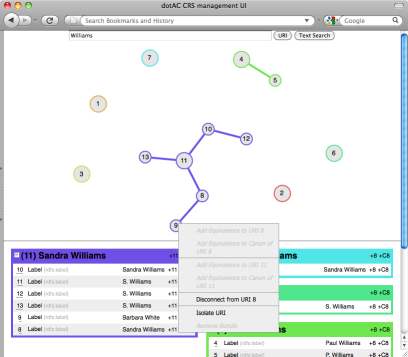
dotAC Coreference Editor
The coreference editor is a graphical tool that enables a user to select resources from a Coreference Service and indicate which resources are (and are not) equivalent to each other. The editor consists of two panes: above, a graphical depiction of the selected resources and their equivalences, and below a list of the resources, organised by equivalence class.
To begin, the user searches for a resource URI or for a literal value; in the latter case, all resources with matching property values are retrieved and added to the editor.
In the upper pane, groups of equivalent resources are shown as connected components (trees) of the graph. The currently selected resource is indicated by an larger circle. As the user selects different resources in the graph, the groups in the lower pane are reorganised; the lower left pane indicates the equivalence class containing the selected resources, with the selected resource being highlighted within the group. The lower right pane lists the remaining groups.
The groups is the lower pane may be expanded or collapsed for clarity, as may individual resources within a group (for example, to show variant name forms associated with a particular resource).
When a user clicks on a resource, a toolbar appears which allows the user to form a link to another resource (by clicking on it), break a link with an adjacent resource (by clocking on the adjacent resource) or isolate the resource (so breaking all links with adjacent resources).
When the equivalence classes are to the user’s satisfaction, the state of the edited resources and their equivalences may be uploaded to the CRS using the save icon. Alternatively, the user may discard changes using the start over (waste bin) icon.
Knowledge Bases
dotAC contains three knowledge bases, which drive the explorer interface and consist of data harvested from a variety of sources:
Each of these knowledge bases is described using both VoID and Semantic Sitemaps.
Links to working prototypes:
- dotAC Explorer
- dotAC Coreference Editor
- dotAC Knowledge Base
- JISC Project Knowledge Base
- OAI (ROAR) Knowledge Base
Link to end user documentation:
Link to code repository or API:
http://forge.ecs.soton.ac.uk/projects/dotac/
Link to technical documentation:
Date prototype was launched:
29 November 2009 (code under constant evolution for duration of project)
Project Team Names, Emails and Organisations:
- Nicholas Gibbins, nmg@ecs.soton.ac.uk, University of Southampton
- Les Carr, lac@ecs.soton.ac.uk, University of Southampton
- Hugh Glaser, hg@ecs.soton.ac.uk, University of Southampton
- Ian Millard, icm@ecs.soton.ac.uk, University of Southampton
- Marcus Cobden, mc08r@ecs.soton.ac.uk, University of Southampton
Project Website:
PIMS entry:
https://pims.jisc.ac.uk/projects/view/1355
Table of Contents for Project Posts
- Project Evaluation
- User Participation
- Day-to-Day Work
- Technical Standards
- Value Add
- Small WINs and FAILs