Now that the season of mists and mellow fruitfulness is upon us, most of our colleagues are busy preparing for the new intake of undergraduates. We’ve also been busy on dotAC, with a number of parallel threads coming together nicely, and some interesting discussions with our counterparts on related projects.
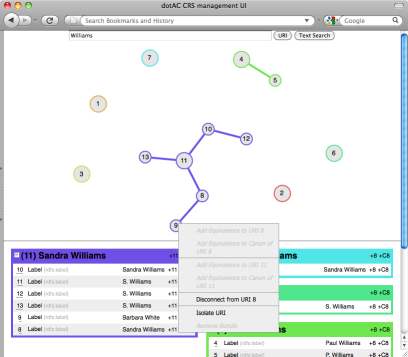
The frontend for the coreference service now resembles something that we’re happy to inflict on our trial users, thanks to Marcus’s sterling work. In the screenshot below, you can see a number of bundles (groups of possibly-related resources) displayed as connected graph components. Each node represents a resource with a unique URI, and the edges between resources are a representation of the equivalence statements that allow us to stitch together the scattered parts of the Web of Linked Data.
In this example, we’ve retrieved a number of bundles that relate to people with the surname Williams. The bundles you see are the result of automated processes that have identified likely coreferent resources; unfortunately, bitter experience has taught us that such automated techniques are defeasible, so it’s frequently necessary for people to check over the data for inconsistencies. In the centre of the screen is a bundle of resources that we think represent Sandra Williams. The resource labelled “11” is used as the canonical resource for Sandra, and is shown as larger than the rest of the resources. However, this bundle contains a ringer: the resource labelled “8” refers to someone other than Sandra, so we’re disconnecting it from the rest of the bundle.
When we’re happy with the state of the bundles in the editor, we can synchronise our session back with the CRS, for other applications (including the explorer interface that we’re building on top of RKBExplorer) to use.
Last week, Nick travelled up to Bristol for a workshop at ILRT organised by Nikki Rogers of the ResearchRevealed project. Also present were members of BRII and Readiness4REF – the link between these projects is that we’re all looking at using CRIS data in CERIF format.
Slideshare plug-in provided by rob
The experiences of the other projects seem rather to mirror our own; plenty of people are talking about CERIF, but very few seem to be using it, partly due to the lack of documentation, and partly due to perceived weaknesses in the underlying model (as implemented in the EuroCRIS-supplied database schema). The likelihood that CERIF or similar ends up being used for the REF now looks increasingly remote; there probably isn’t sufficient time for both implementation and the necessary shakedown period after the HEFCE guidance is issued in early 2010.
This said, the workshop was very helpful. Despite its flaws, CERIF is addressing the right domain, and there was interest in mapping CERIF’s model onto other formats, particularly those based on RDF. Ben O’Steen of BRII gave a presentation that mirrors our design decisions for this mapping; rather than invent yet another ontology, best practice (at least as far as the Linked Data Web is concerned) is to reuse fragments of whatever widely-used ontologies seem to fit. Ben’s name for this – Frankenstein ontologies – is apt enough that we’ve been using it ourselves.