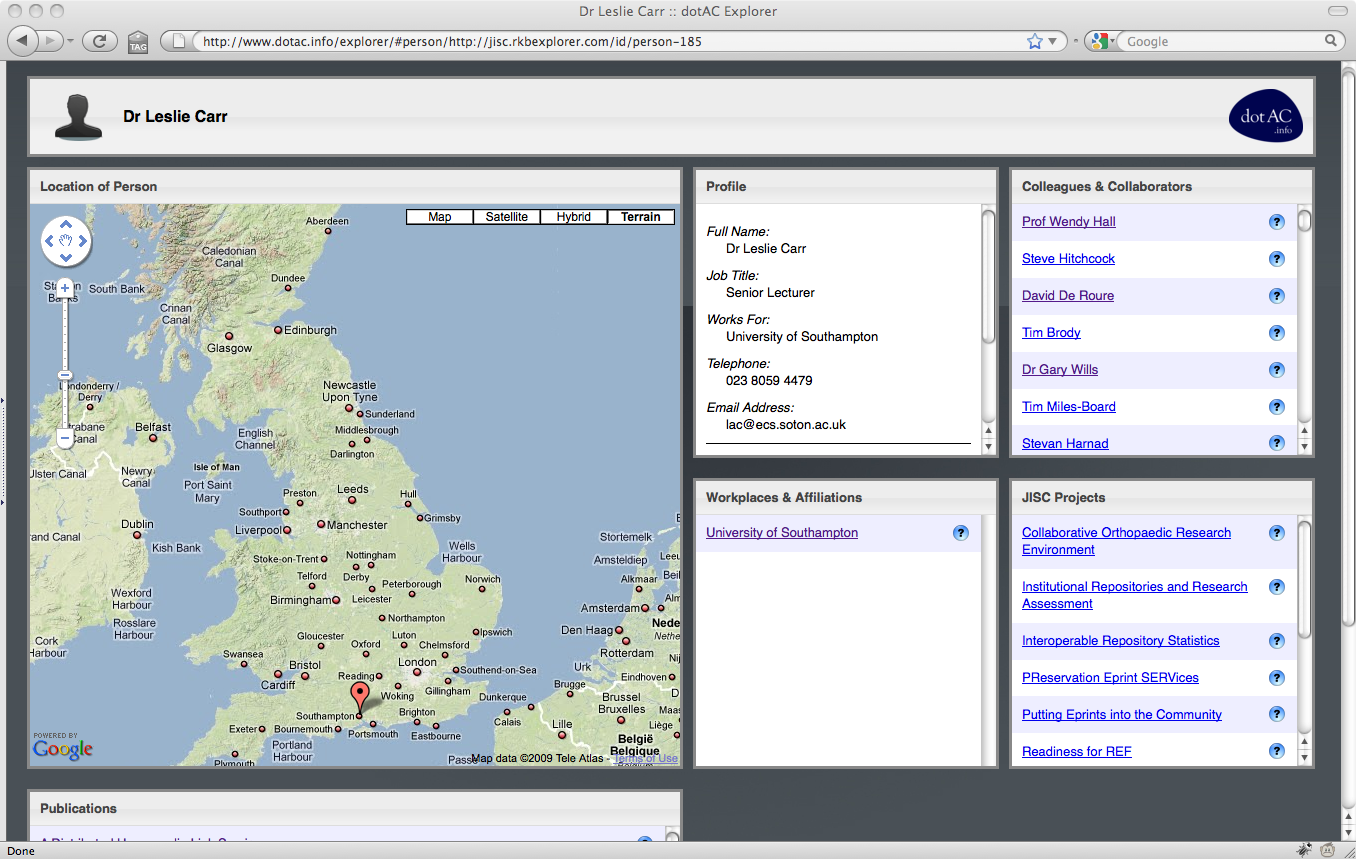
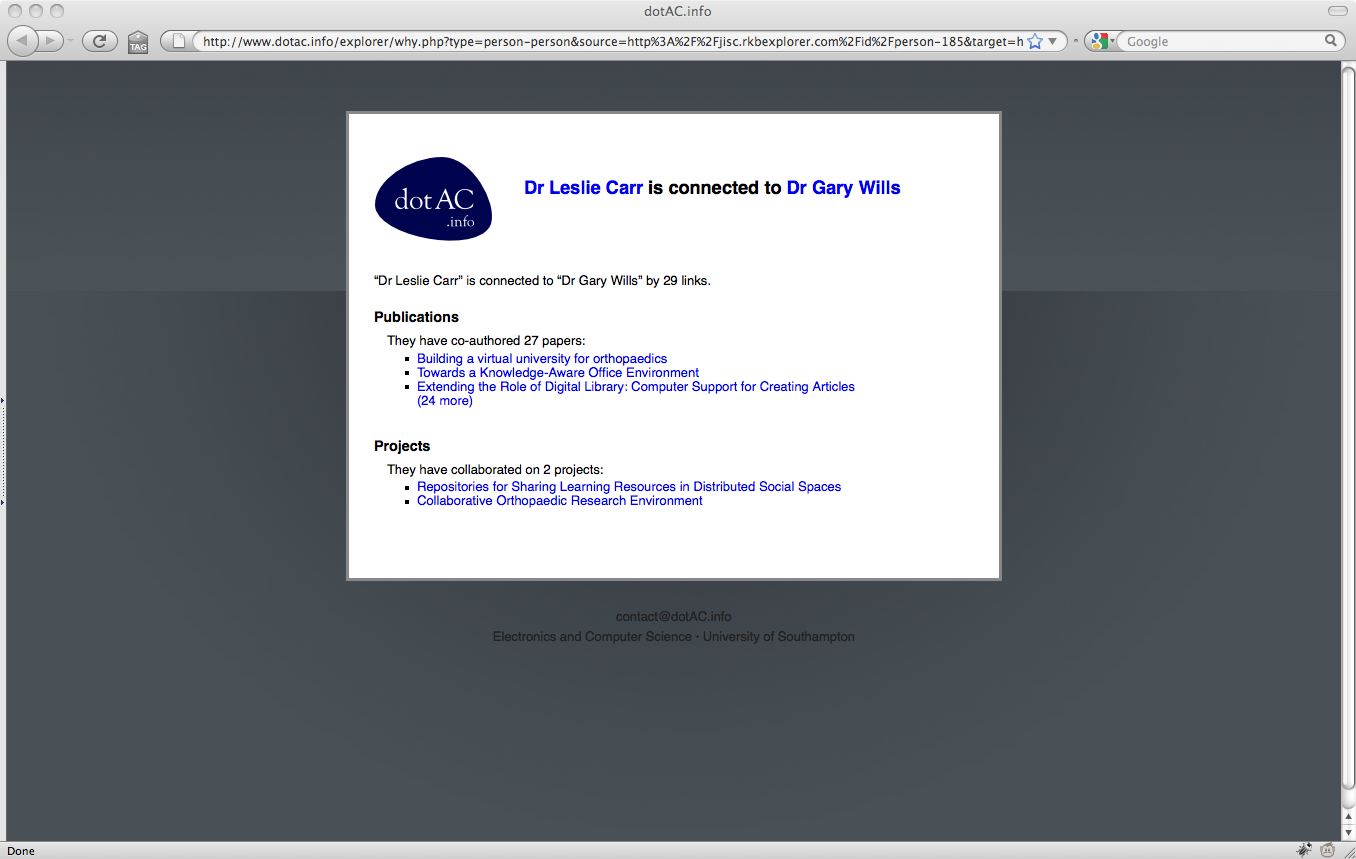
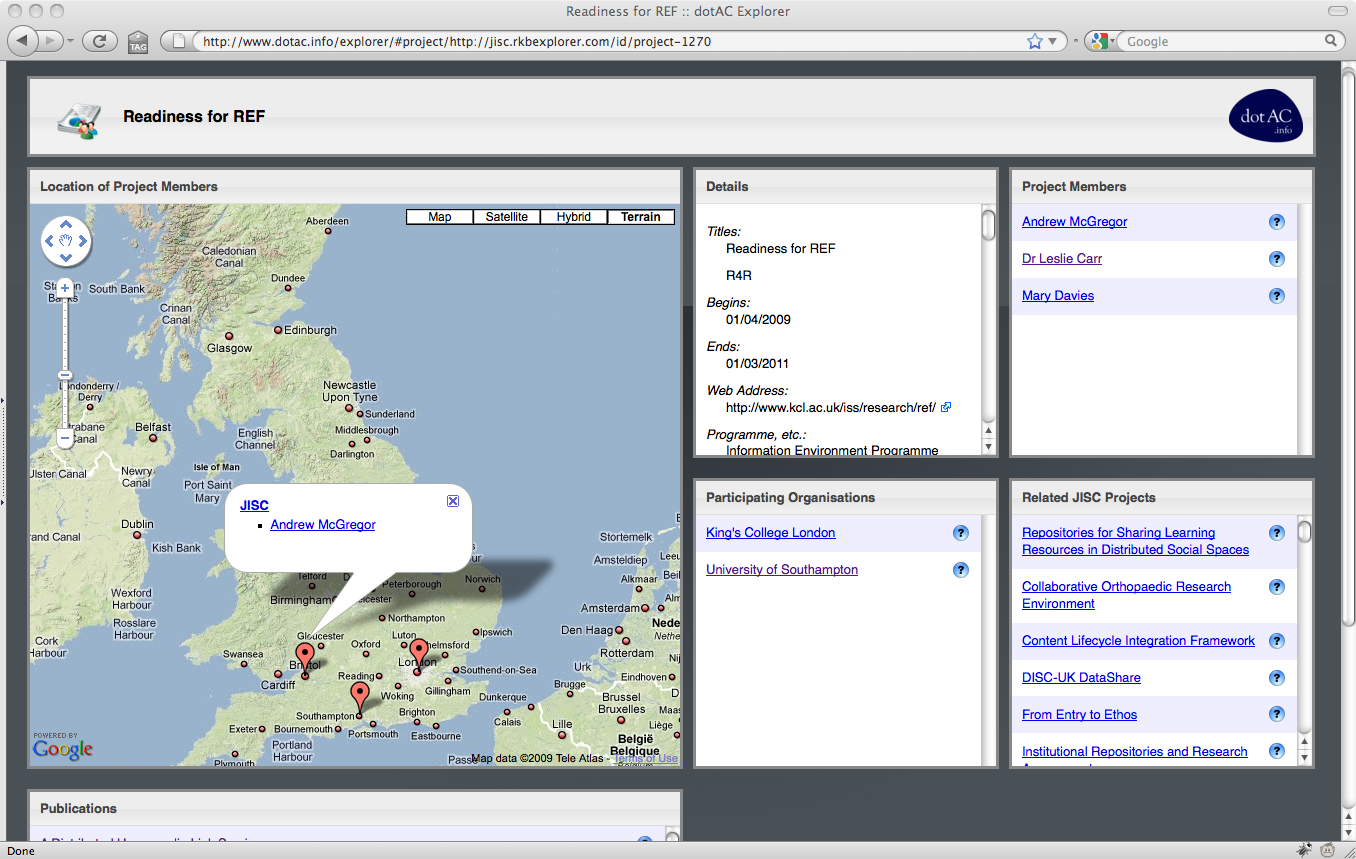
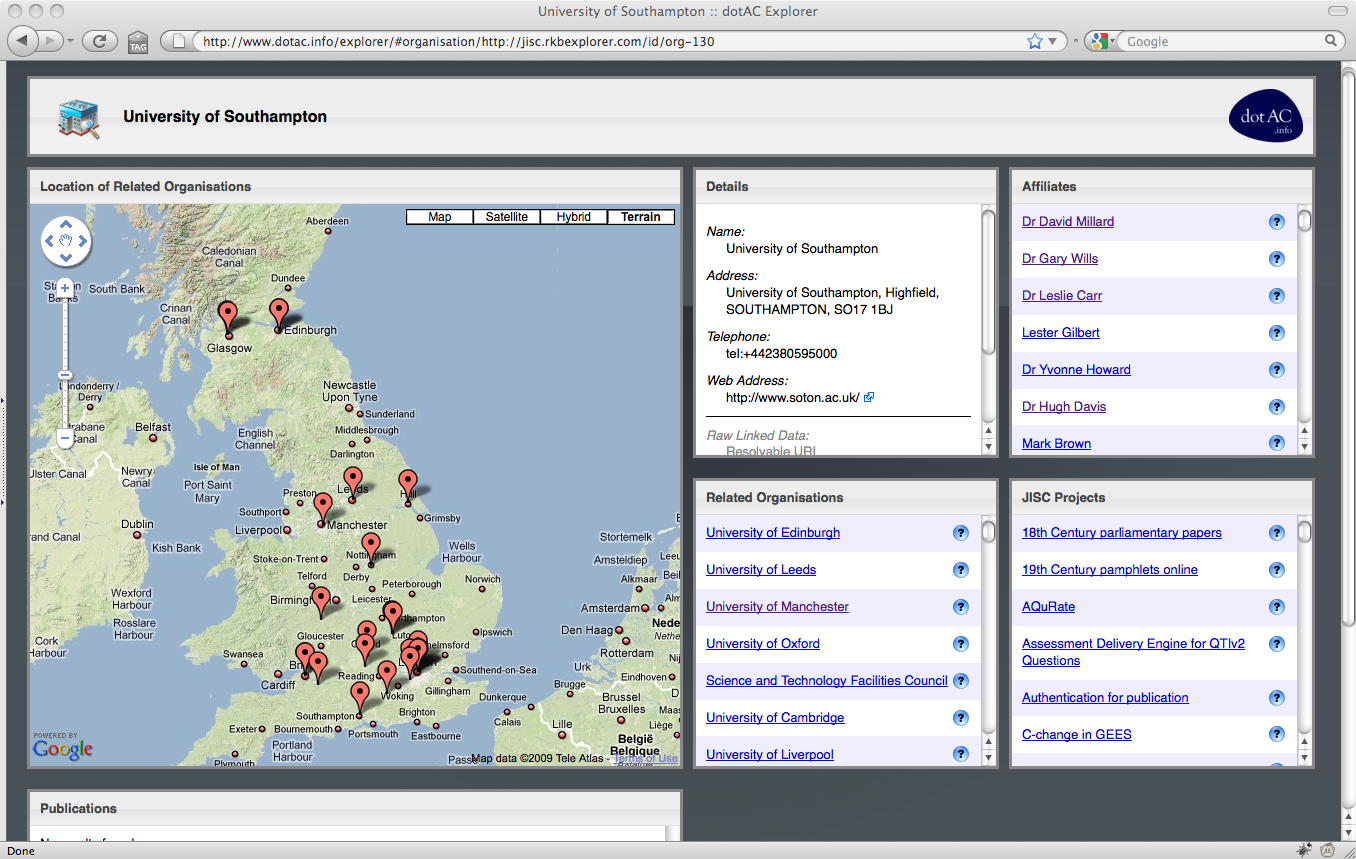
When we were writing the proposal for this project, we identified three use cases that summarised the needs that we were trying to meet. In the grand tradition of eating one’s own dogfood, we chose use cases to which we could readily relate:
Use Case 1: A researcher trying to identify potential project partners
The first use case is based on the experiences of a researcher who is trying to initiate collaborative research in an unfamiliar domain; while they could be expected to have a reasonable awareness of developments in their own domain, they are unlikely to know much about a different domain. In order to successfully identify potential partners, they need to know who is working in the area of interest (and what their track record is like), and what other projects and collaborations currently exist.
Use Case 2: A research postgraduate student
A research postgraduate’s requirements are ostensibly similar to those of a researcher, but they are less likely to be familiar with their own domain. They need to get an overview of the current developments in their field, and some sense of who the ‘top’ researchers are, along with their communities of practice.
Use Case 3: A research council manager
A research council manager needs to have awareness of the field for whose funding they are responsible, so their requirements are similar to those of the researcher, but they also need some way of determining the effectiveness of funding (possibly by considering the quality and quantity of research outputs), particularly in interdisciplinary areas, and of the geographical distribution of funding.
These use cases were derived from those that we used when building CS AKTive Space back in 2003; Use Case 3 in particular was derived from some contract work that we carried out for EPSRC (analysing the outcomes of funding in the Life Sciences Interface).
Although the JISCRI instructions state “you are not the end user”, we’d dispute this. With our researcher hats on (as opposed to our developer hats), we very much fit the first two cases; to put it a different way, we have an itch that we’ve been trying to scratch for some time. We also hope that the JISC programme managers recognise the third use case – their EPSRC counterparts certainly did.
However, we’ve become aware that this is not an exhaustive set of use cases, and that we’d ignored one group of potential users, namely the administrators of the repositories and research information systems that we’re relying on to provide us with our data.
To give an illustrative motivating scenario, consider the following:
At Southampton, we think that we’re pretty savvy about all things repository-related. We have an institutional archiving mandate, and all PhD students are now required to deposit electronic copies of their theses before they’re allowed to graduate. We’ve relied on our repositories (both at a University level, and within Schools) to manage our publications submission for the 2008 RAE.
We also think that we’re pretty knowledgeable about linked data, and the need to give things unique and dependable identifiers.
When the University was preparing for the last RAE, it hit a problem. When an eprint was deposited, we had good information about the author that submitted it (namely, that they were a current member of the University), but information about the remaining authors was frequently sketchy; quite often, we didn’t know whether the other authors were current students or staff, former students or staff, or completely external to the University.
The job of fixing this eventually fell to the staff in the library, who had the unenviable and time-consuming task of working out into which category the authors on every paper fell, and whether or not they were the same as any previously identified authors (the co-reference problem).
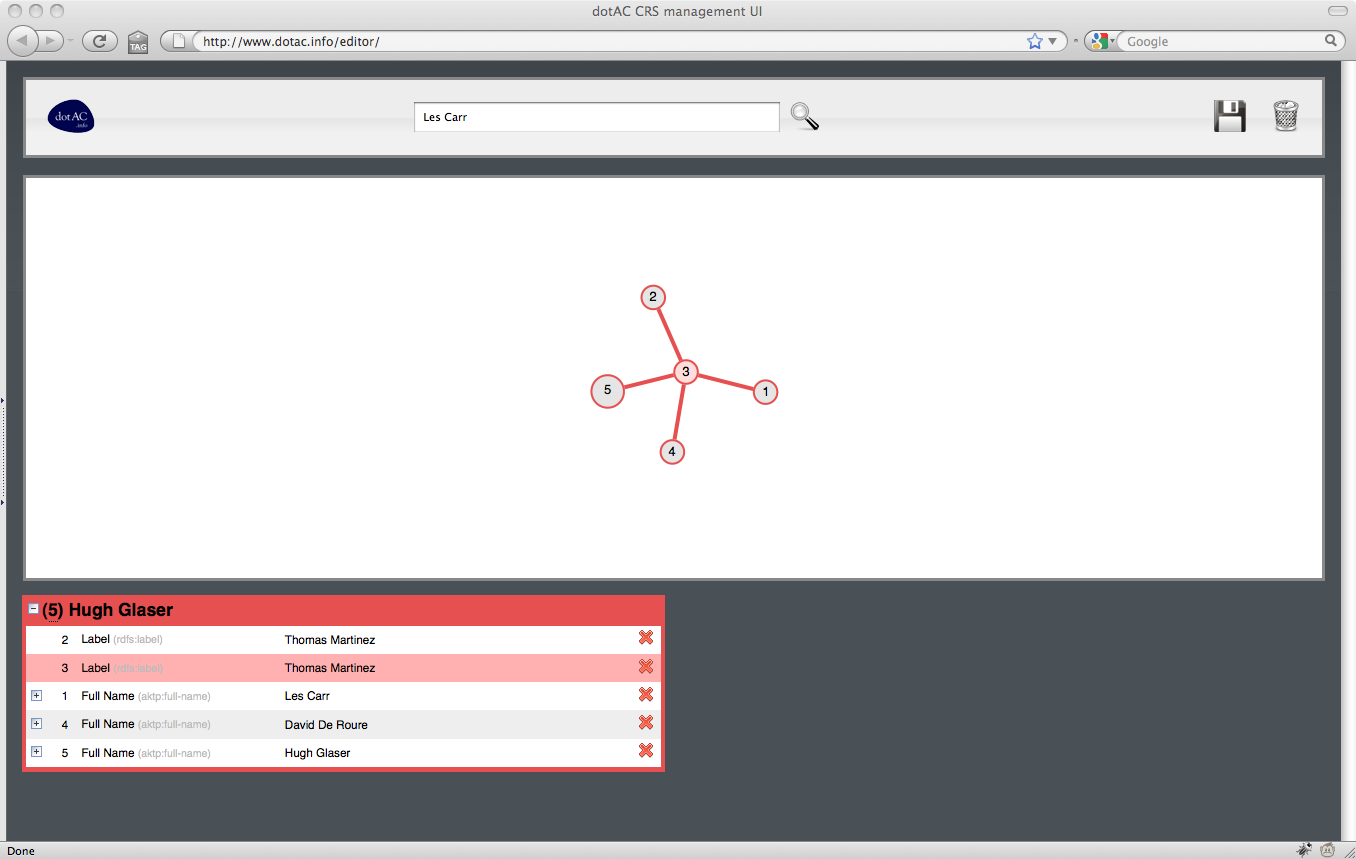
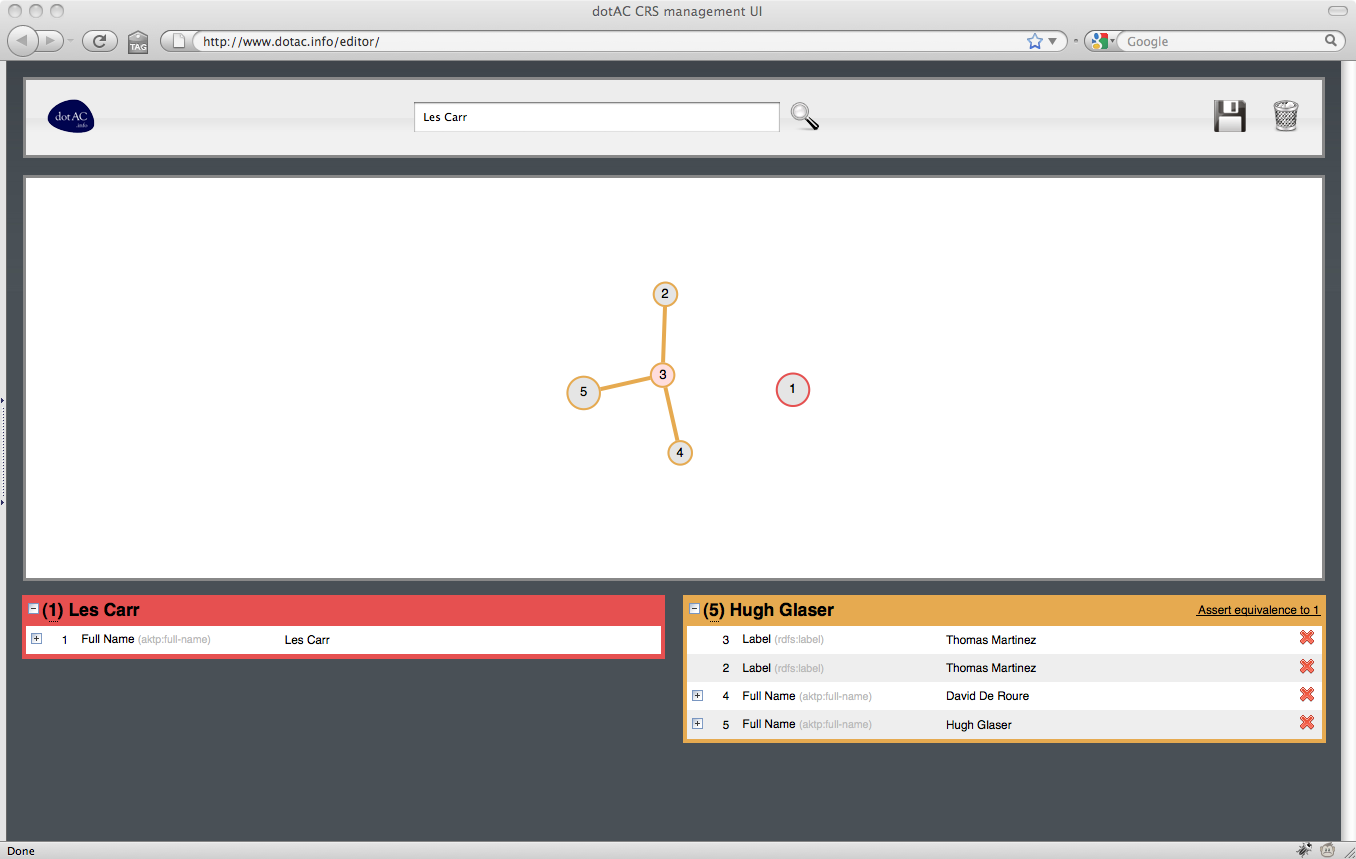
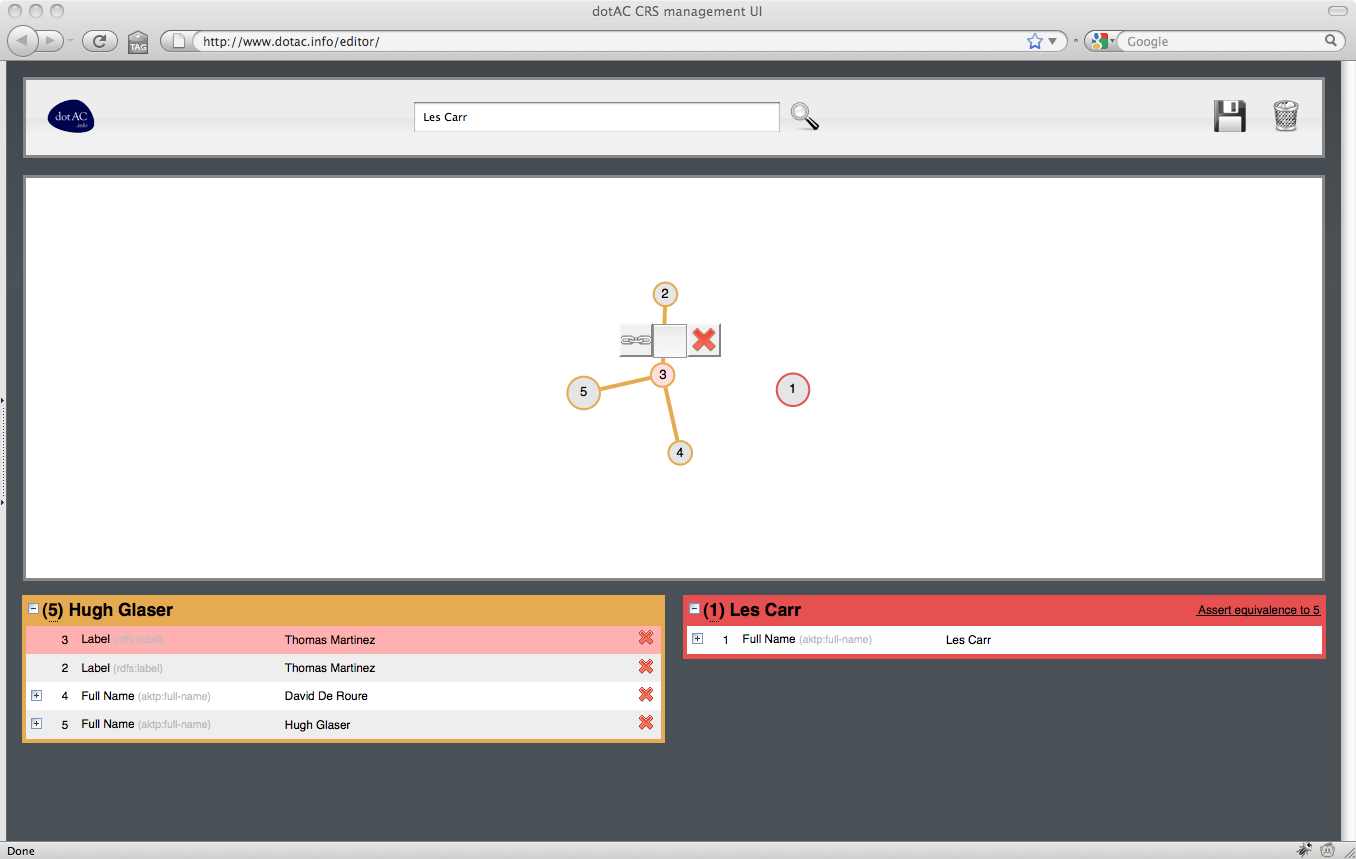
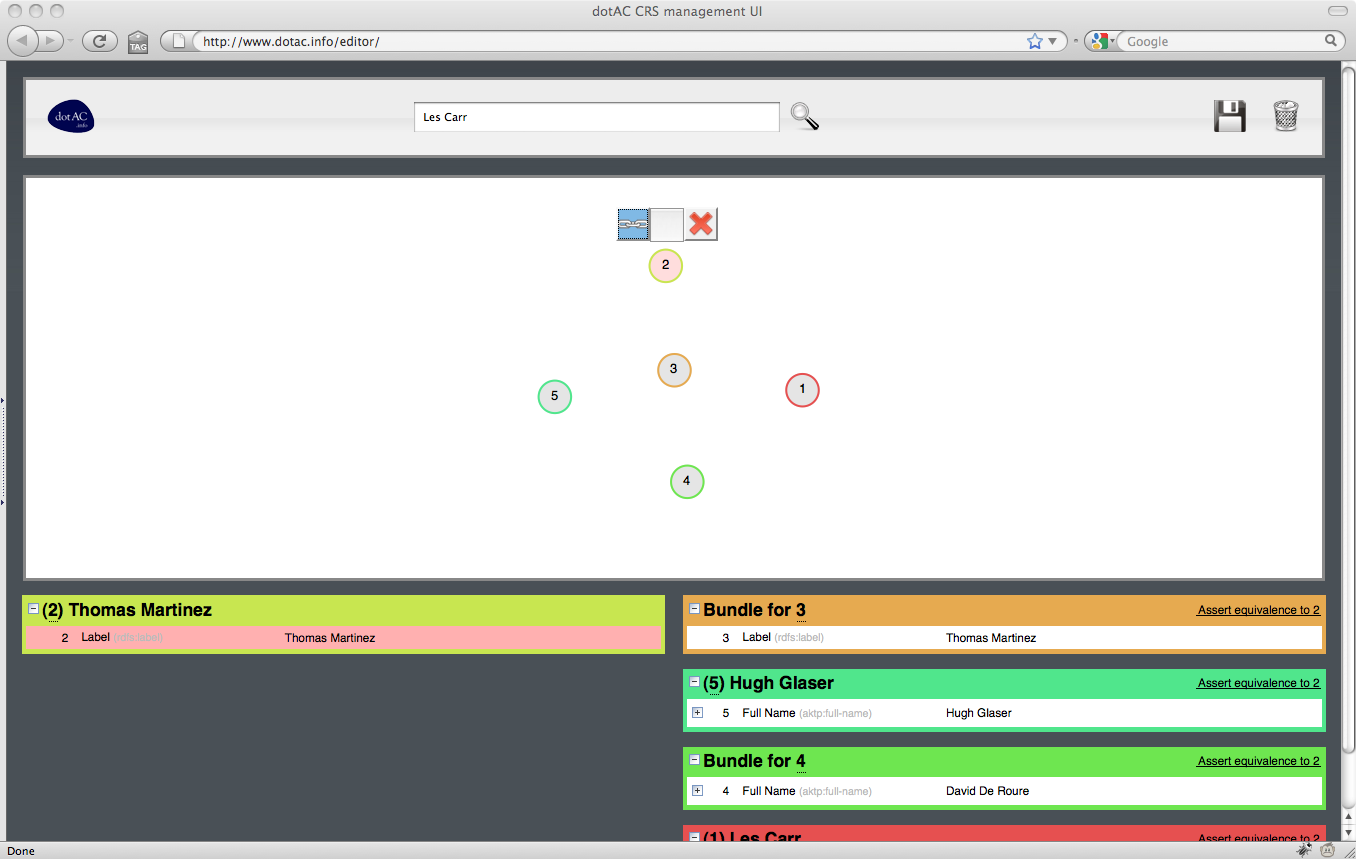
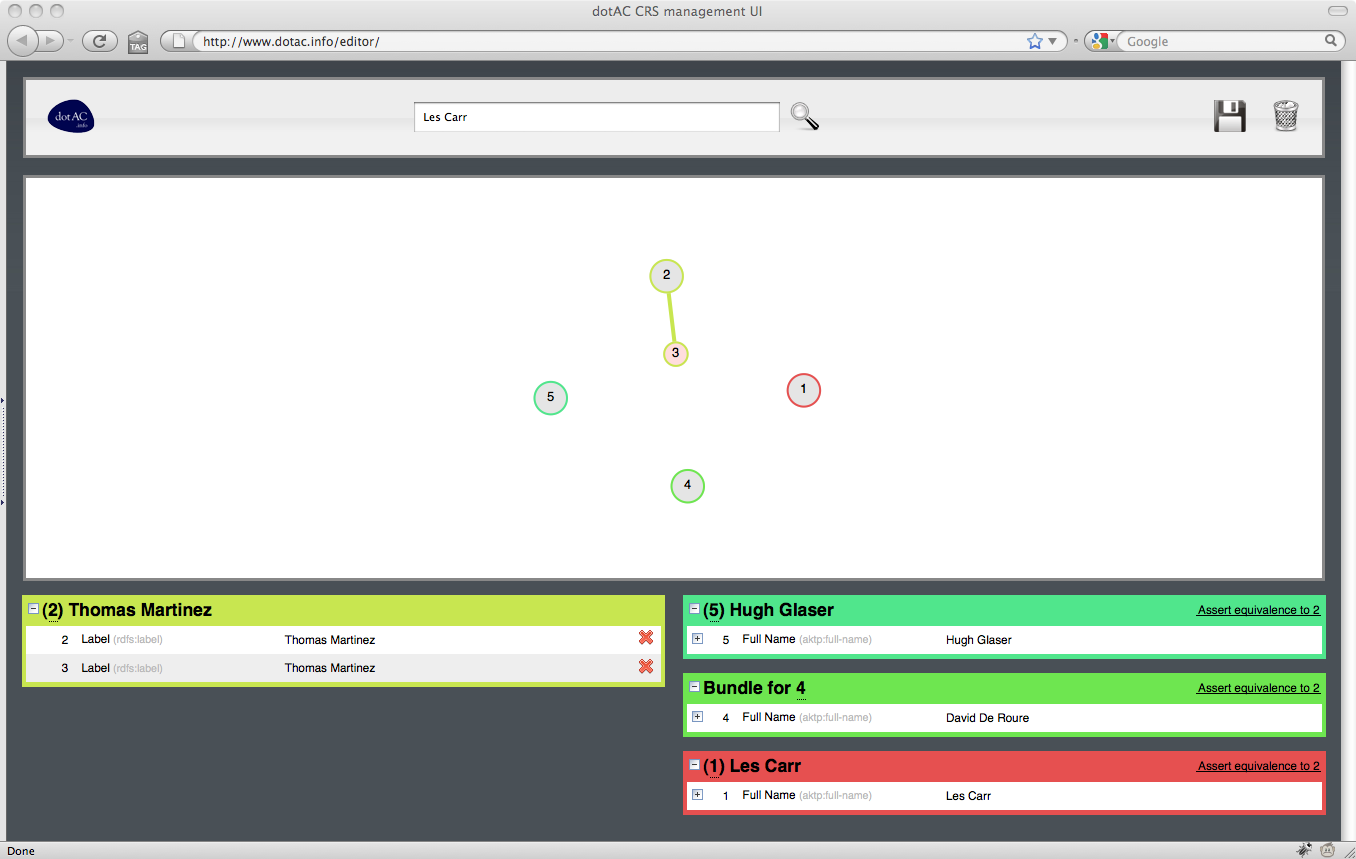
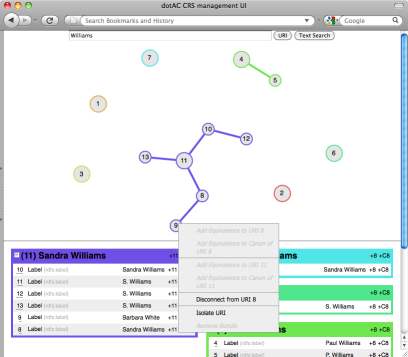
Following the similar work that Nick did on AKT, and the subsequent work that Hugh and Ian did on Co-Reference Services for the Semantic Web, we’ve come to the conclusion that this is a job that is best done as close to the source of the data as possible. The graphical editor mentioned in our September post is our attempt to build a UI for the CRS that makes the job of co-reference resolution as easy as possible for non-Linked Data experts.
Use Case 4: a repository manager
A repository manager needs to publish data about the deposits in their repository in a form that’s of most use to the prospective users of that data. For the users in Use Cases 1-3 to get a comprehensive view of UKHE that will satisfy their information needs, a repository manager must ensure that their published data links up with other that from other sources.
If we are our own subjects for Use Cases 1 and 2, and our programme manager is our subject for Use Case 3, our subjects for Use Case 3 come from the University library: Fiona Nichols, the liaison librarian for computer science, and Isobel Stark, the liaison librarian for chemistry. Both Fiona and Isobel were involved in the pre-RAE data cleaning effort, and they’ve provided some useful insights on the process from a library perspective, and feedback on the prototype of the CRS editor.
We’re also planning an dotAC-based adjunct to a future EPrints training day to replace the one that we had to cancel in order to attend the JISCRI workshop in Manchester, which should give us an opportunity to push the Linked Data idea (and try out our tools) on a broader audience. Watch this space.